Summary: What should I do to print correctly a string literal defined in the source code that was stored in UTF-8 encoding (Windows CP 65001) to a cmd console using std::cout stream?
Motivation: I would like to modify the excellent Catch unit-testing framework (as an experiment) so that it would display my texts with accented characters. The modification should be simple, reliable, and should be also useful for other languages and working environments so that it could be accepted by the author as an enhancement. Or if you know Catch and if there is some alternative solution, could you post it?
Details: Let's start with the Czech version of the "quick brown fox..."
#include <iostream>
#include "windows.h"
using namespace std;
int main()
{
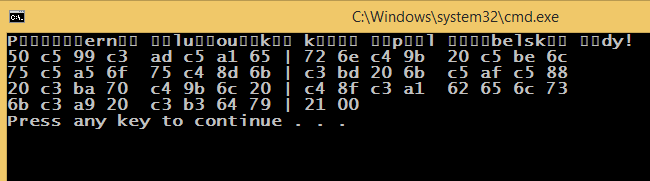
cout << "\n-------------------------- default cmd encoding = 852 -------------------\n";
cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << endl;
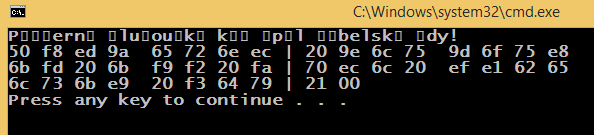
cout << "\n-------- Windows Central European (1250) set for the cmd console --------\n";
SetConsoleOutputCP(1250);
std::cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << std::endl;
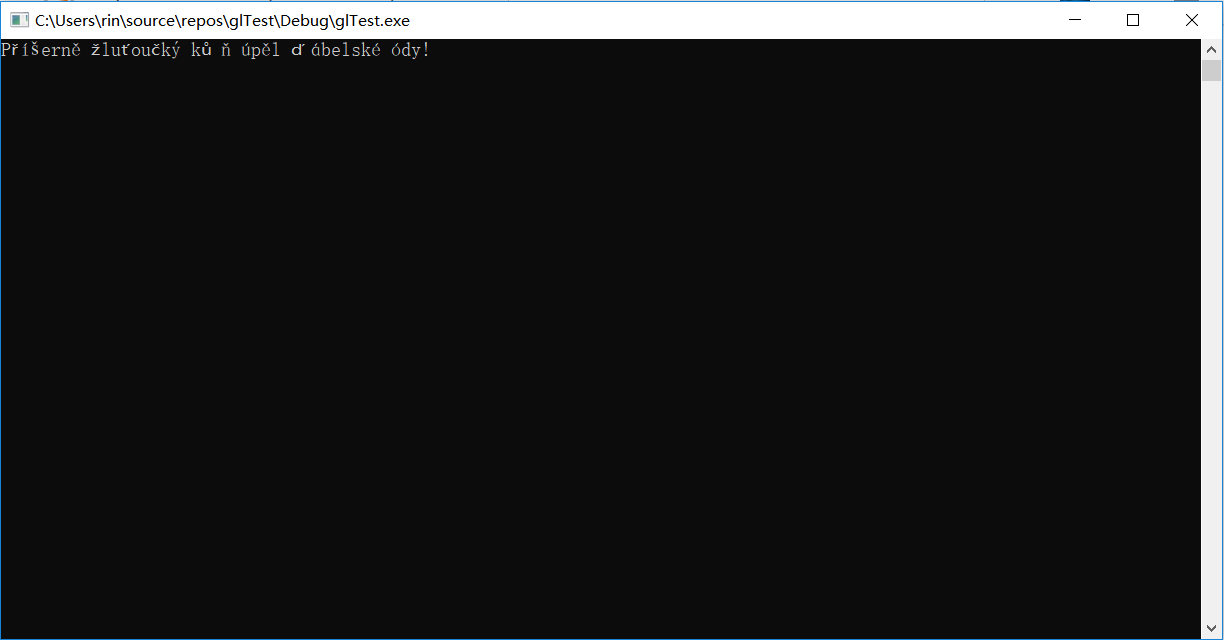
cout << "\n------------- Windows UTF-8 (65001) set for the cmd console -------------\n";
SetConsoleOutputCP(CP_UTF8);
std::cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << std::endl;
}
It prints the following (font set to Lucida Console): 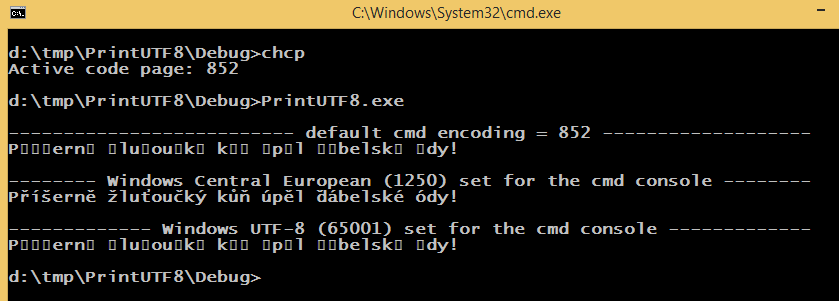
The cmd default encoding is 852, the default windows encoding is 1250, and the source code was saved using 65001 encoding (UTF-8 with BOM). The SetConsoleOutputCP(1250); changes the cmd encoding (programmatically) the same way as the chcp 1250 does.
Observation: When setting the 1250 encoding, the UTF-8 string literal is printed correctly. I believe it can be explained, but it is really strange. Is there any decent, human, general way to solve the problem?
Update: The "narrow string literal" is stored using Windows-1250 encoding in my case (native Windows encoding for Central European). It seems to be independent on the encoding of the source code. The compiler saves it in the windows native encoding. Because of that, switching cmd to that encoding gives the desired output. It is uggly, but how can I get the native windows encoding programmatically (to pass it to the SetConsoleOutputCP(cpX))? What I need is a constant that is valid for the machine where the compilation happened. It should not be a native encoding for the machine where the executable runs.
The C++11 introduced also u8"the UTF-8 string literal", but it does not seem to fit with SetConsoleOutputCP(CP_UTF8);