Note: the code behind this answer can be found here.
Suppose we have some data sampled from two different groups, red and blue:
![enter image description here]()
Here, we can see which data point belongs to the red or blue group. This makes it easy to find the parameters that characterise each group. For example, the mean of the red group is around 3, the mean of the blue group is around 7 (and we could find the exact means if we wanted).
This is, generally speaking, known as maximum likelihood estimation. Given some data, we compute the value of a parameter (or parameters) that best explains that data.
Now imagine that we cannot see which value was sampled from which group. Everything looks purple to us:
![enter image description here]()
Here we have the knowledge that there are two groups of values, but we don't know which group any particular value belongs to.
Can we still estimate the means for the red group and blue group that best fit this data?
Yes, often we can! Expectation Maximisation gives us a way to do it. The very general idea behind the algorithm is this:
- Start with an initial estimate of what each parameter might be.
- Compute the likelihood that each parameter produces the data point.
- Calculate weights for each data point indicating whether it is more red or more blue based on the likelihood of it being produced by a parameter. Combine the weights with the data (expectation).
- Compute a better estimate for the parameters using the weight-adjusted data (maximisation).
- Repeat steps 2 to 4 until the parameter estimate converges (the process stops producing a different estimate).
These steps need some further explanation, so I'll walk through the problem described above.
Example: estimating mean and standard deviation
I'll use Python in this example, but the code should be fairly easy to understand if you're not familiar with this language.
Suppose we have two groups, red and blue, with the values distributed as in the image above. Specifically, each group contains a value drawn from a normal distribution with the following parameters:
import numpy as np
from scipy import stats
np.random.seed(110) # for reproducible results
# set parameters
red_mean = 3
red_std = 0.8
blue_mean = 7
blue_std = 2
# draw 20 samples from normal distributions with red/blue parameters
red = np.random.normal(red_mean, red_std, size=20)
blue = np.random.normal(blue_mean, blue_std, size=20)
both_colours = np.sort(np.concatenate((red, blue))) # for later use...
Here is an image of these red and blue groups again (to save you from having to scroll up):
![enter image description here]()
When we can see the colour of each point (i.e. which group it belongs to), it's very easy to estimate the mean and standard deviation for each each group. We just pass the red and blue values to the builtin functions in NumPy. For example:
>>> np.mean(red)
2.802
>>> np.std(red)
0.871
>>> np.mean(blue)
6.932
>>> np.std(blue)
2.195
But what if we can't see the colours of the points? That is, instead of red or blue, every point has been coloured purple.
To try and recover the mean and standard deviation parameters for the red and blue groups, we can use Expectation Maximisation.
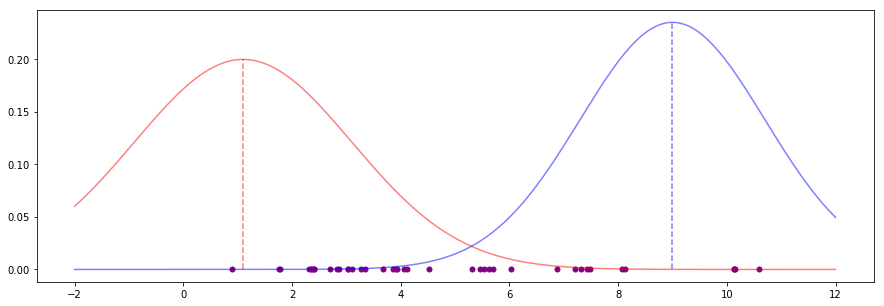
Our first step (step 1 above) is to guess at the parameter values for each group's mean and standard deviation. We don't have to guess intelligently; we can pick any numbers we like:
# estimates for the mean
red_mean_guess = 1.1
blue_mean_guess = 9
# estimates for the standard deviation
red_std_guess = 2
blue_std_guess = 1.7
These parameter estimates produce bell curves that look like this:
![enter image description here]()
These are bad estimates. Both means (the vertical dotted lines) look far off any kind of "middle" for sensible groups of points, for instance. We want to improve these estimates.
The next step (step 2) is to compute the likelihood of each data point appearing under the current parameter guesses:
likelihood_of_red = stats.norm(red_mean_guess, red_std_guess).pdf(both_colours)
likelihood_of_blue = stats.norm(blue_mean_guess, blue_std_guess).pdf(both_colours)
Here, we have simply put each data point into the probability density function for a normal distribution using our current guesses at the mean and standard deviation for red and blue. This tells us, for example, that with our current guesses the data point at 1.761 is much more likely to be red (0.189) than blue (0.00003).
For each data point, we can turn these two likelihood values into weights (step 3) so that they sum to 1 as follows:
likelihood_total = likelihood_of_red + likelihood_of_blue
red_weight = likelihood_of_red / likelihood_total
blue_weight = likelihood_of_blue / likelihood_total
With our current estimates and our newly-computed weights, we can now compute new estimates for the mean and standard deviation of the red and blue groups (step 4).
We twice compute the mean and standard deviation using all data points, but with the different weightings: once for the red weights and once for the blue weights.
The key bit of intuition is that the greater the weight of a colour on a data point, the more the data point influences the next estimates for that colour's parameters. This has the effect of "pulling" the parameters in the right direction.
def estimate_mean(data, weight):
"""
For each data point, multiply the point by the probability it
was drawn from the colour's distribution (its "weight").
Divide by the total weight: essentially, we're finding where
the weight is centred among our data points.
"""
return np.sum(data * weight) / np.sum(weight)
def estimate_std(data, weight, mean):
"""
For each data point, multiply the point's squared difference
from a mean value by the probability it was drawn from
that distribution (its "weight").
Divide by the total weight: essentially, we're finding where
the weight is centred among the values for the difference of
each data point from the mean.
This is the estimate of the variance, take the positive square
root to find the standard deviation.
"""
variance = np.sum(weight * (data - mean)**2) / np.sum(weight)
return np.sqrt(variance)
# new estimates for standard deviation
blue_std_guess = estimate_std(both_colours, blue_weight, blue_mean_guess)
red_std_guess = estimate_std(both_colours, red_weight, red_mean_guess)
# new estimates for mean
red_mean_guess = estimate_mean(both_colours, red_weight)
blue_mean_guess = estimate_mean(both_colours, blue_weight)
We have new estimates for the parameters. To improve them again, we can jump back to step 2 and repeat the process. We do this until the estimates converge, or after some number of iterations have been performed (step 5).
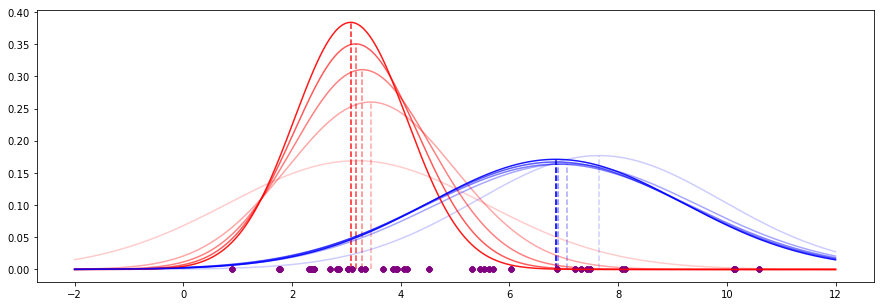
For our data, the first five iterations of this process look like this (recent iterations have stronger appearance):
![enter image description here]()
We see that the means are already converging on some values, and the shapes of the curves (governed by the standard deviation) are also becoming more stable.
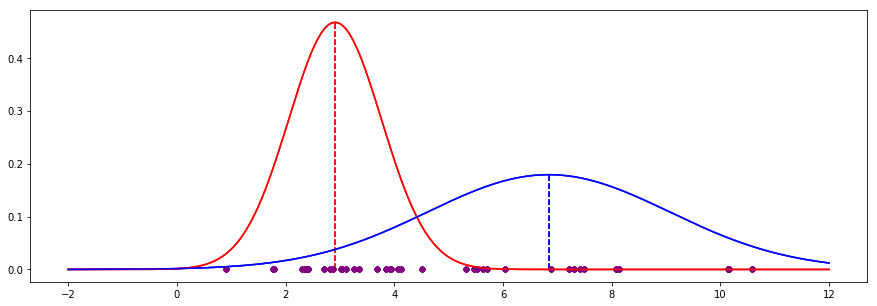
If we continue for 20 iterations, we end up with the following:
![enter image description here]()
The EM process has converged to the following values, which turn out to very close to the actual values (where we can see the colours - no hidden variables):
| EM guess | Actual | Delta
----------+----------+--------+-------
Red mean | 2.910 | 2.802 | 0.108
Red std | 0.854 | 0.871 | -0.017
Blue mean | 6.838 | 6.932 | -0.094
Blue std | 2.227 | 2.195 | 0.032
In the code above you may have noticed that the new estimation for standard deviation was computed using the previous iteration's estimate for the mean. Ultimately it does not matter if we compute a new value for the mean first as we are just finding the (weighted) variance of values around some central point. We will still see the estimates for the parameters converge.