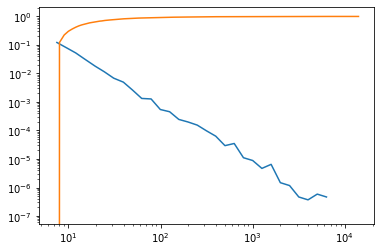
I am considering the number of occurrence of unique words in the Moby Dick novel and using the powerlaw python package to fit words’ frequencies to a power law.
I am not sure why I can't recapitulate the results from previous work by Clauset et al. as both the p-value and the KS score are "bad".
The idea is to fit the frequencies of unique words into a power law. However, the Kolmogorov-Smirnov tests for goodness of fit calculated by scipy.stats.kstest look terrible.
I have the following function to fit data to a power law:
import numpy as np
import powerlaw
import scipy
from scipy import stats
def fit_x(x):
fit = powerlaw.Fit(x, discrete=True)
alpha = fit.power_law.alpha
xmin = fit.power_law.xmin
print('powerlaw', scipy.stats.kstest(x, "powerlaw", args=(alpha, xmin), N=len(x)))
print('lognorm', scipy.stats.kstest(x, "lognorm", args=(np.mean(x), np.std(x)), N=len(x)))
Downloading the frequency of unique words in the novel Moby Dick by Herman Melville (supposed to follow a power law according to Aaron Clauset et al.):
wget http://tuvalu.santafe.edu/~aaronc/powerlaws/data/words.txt
Python script:
x = np.loadtxt('./words.txt')
fit_x(x)
results:
('powerlaw', KstestResult(statistic=0.862264651286131, pvalue=0.0))
('log norm', KstestResult(statistic=0.9910368602492707, pvalue=0.0))
When I compare the expected results and follow this R tutorial on the same Moby Dick dataset I get a decent p-value and KS test value:
library("poweRlaw")
data("moby", package="poweRlaw")
m_pl = displ$new(moby)
est = estimate_xmin(m_pl)
m_pl$setXmin(est)
bs_p = bootstrap_p(m_pl)
bs_p$p
## [1] 0.6738
What am I missing when computing the KS test values and postprocessing the fit by the powerlaw python library? The PDF and CDF look ok to me, but the KS tests look awry.