I have not been able to reproduce your error, but I strongly suspect the source of the error to be the datatypes. In the Power Query Editor, try transforming your grouping variables to text. The fact that your query fails for a dataset larger than 20000 rows should have absolutely nothing to do with the problem. Unless, of course, the data content somehow changes after row 20000.
If you could describe your datasource and show the applied steps in the Power Query Editor that would be of great help for anyone trying to assist you. You could also try to apply your code one step at a time, meaning making one table using dataset['id'] =dataset.groupby(['RESIDENTIAL_ADDRESS1','RESIDENTIAL_CITY']).ngroup() and yet another table using dataset['household_count'] = dataset.groupby(['id'])['id'].transform('count')
I might as well show you how to do just that, and maybe at the same time cement my suspicion that the error lies in the datatypes and hopefully rule out other error sources.
I'm using numpy along with a few random city and street names to build a dataset that I hope represents the structure and datatypes of your real world dataset:
Snippet 1:
import numpy as np
import pandas as pd
np.random.seed(123)
strt=['Broadway', 'Bowery', 'Houston Street', 'Canal Street', 'Madison', 'Maiden Lane']
city=['New York', 'Chicago', 'Baltimore', 'Victory Boulevard', 'Love Lane', 'Utopia Parkway']
RESIDENTIAL_CITY=np.random.choice(strt,21000).tolist()
RESIDENTIAL_ADDRESS1=np.random.choice(strt,21000).tolist()
sample_dataset=pd.DataFrame({'RESIDENTIAL_CITY':RESIDENTIAL_CITY,
'RESIDENTIAL_ADDRESS1':RESIDENTIAL_ADDRESS1})
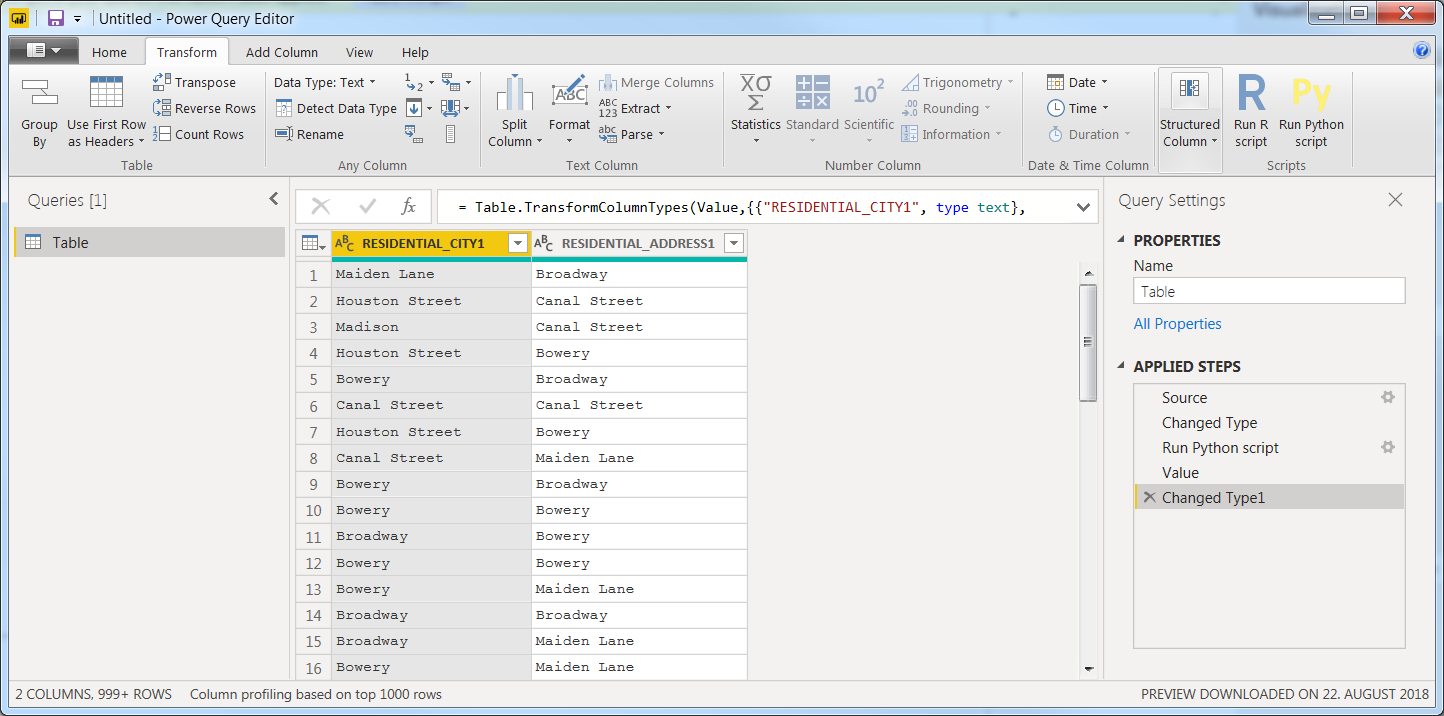
Copy that snippet, go to PowerBI Desktop > Power Query Editor > Transform > Run Python Script and run it to get this:
![enter image description here]()
Then do the same thing with this snippet:
dataset['id'] =dataset.groupby(['RESIDENTIAL_ADDRESS1','RESIDENTIAL_CITY']).ngroup()
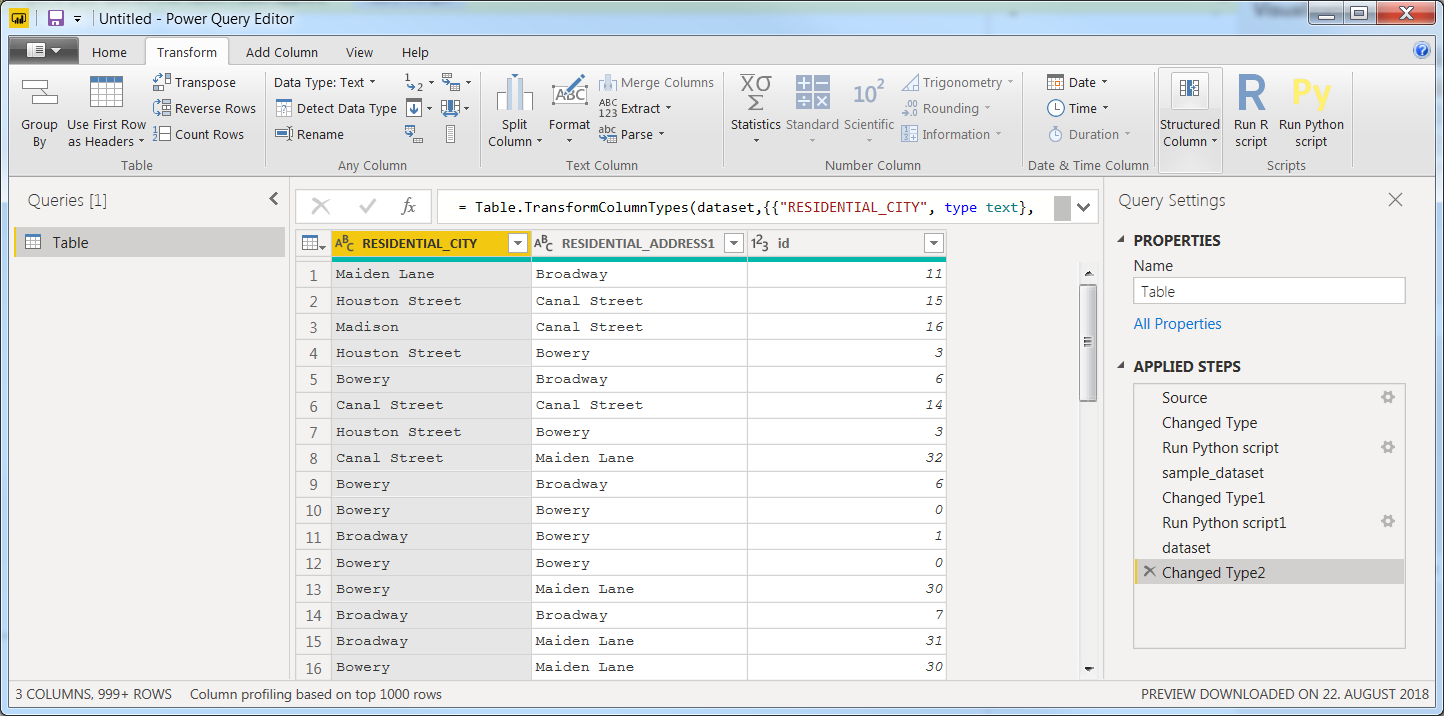
Now you should have this:
![enter image description here]()
So far, your last step is called Changed Type 2. Right above is a step called dataset. If you click that you'll see that the datatype of ID there is a string ABC and that it changes to number 123 in the next step. With my settings, Power BI inserts the step Changed Type 2 automatically. Maybe that is not the case with you? It cerainly can be a potential error source.
Next, insert your last line as a step of it's own:
dataset['household_count'] = dataset.groupby(['id'])['id'].transform('count')
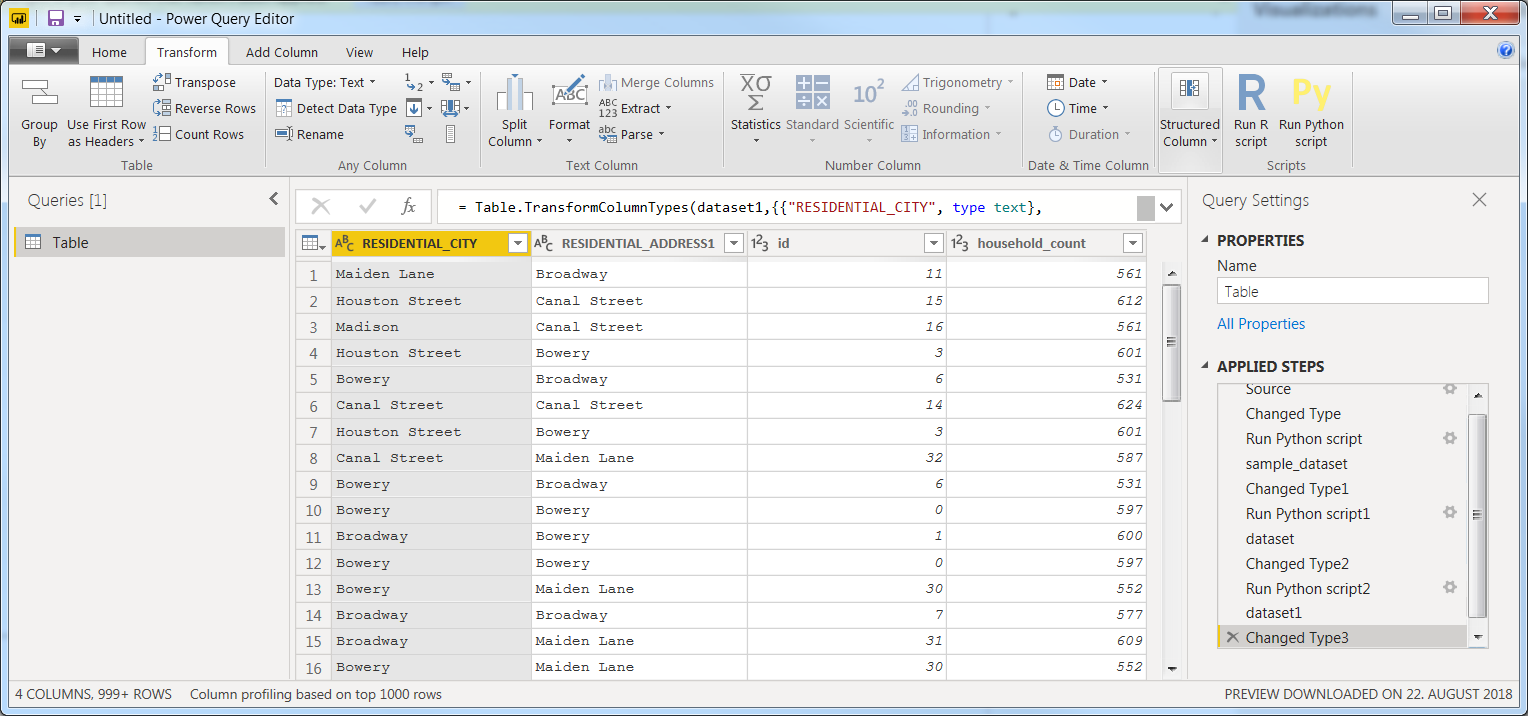
Now you should have the dataset like below, along with the same steps under Applied Steps:
![enter image description here]()
With this setup, everything seems to be working fine. So, what do we know for sure by now?
- The size of the dataset is not the problem
- Your code itself is not the problem
- Python should handle this perfectly in Power BI
And what do we suspect?
- Your data is the problem - either missing values or wrong type
I hope this helps you out somehow. If not, then don't hesitate to let me know.