I'm pushing a stream of data to Azure EventHub with the following code leveraging Microsoft.Hadoop.Avro.. this code runs every 5 seconds, and simply plops the same two Avro serialised items 👍🏼:
var strSchema = File.ReadAllText("schema.json");
var avroSerializer = AvroSerializer.CreateGeneric(strSchema);
var rootSchema = avroSerializer.WriterSchema as RecordSchema;
var itemList = new List<AvroRecord>();
dynamic record_one = new AvroRecord(rootSchema);
record_one.FirstName = "Some";
record_one.LastName = "Guy";
itemList.Add(record_one);
dynamic record_two = new AvroRecord(rootSchema);
record_two.FirstName = "A.";
record_two.LastName = "Person";
itemList.Add(record_two);
using (var buffer = new MemoryStream())
{
using (var writer = AvroContainer.CreateGenericWriter(strSchema, buffer, Codec.Null))
{
using (var streamWriter = new SequentialWriter<object>(writer, itemList.Count))
{
foreach (var item in itemList)
{
streamWriter.Write(item);
}
}
}
eventHubClient.SendAsync(new EventData(buffer.ToArray()));
}
The schema used here is, again, v. simple:
{
"type": "record",
"name": "User",
"namespace": "SerDes",
"fields": [
{
"name": "FirstName",
"type": "string"
},
{
"name": "LastName",
"type": "string"
}
]
}
I have validated this is all good, with a simple view in Azure Stream Analytics on the portal:
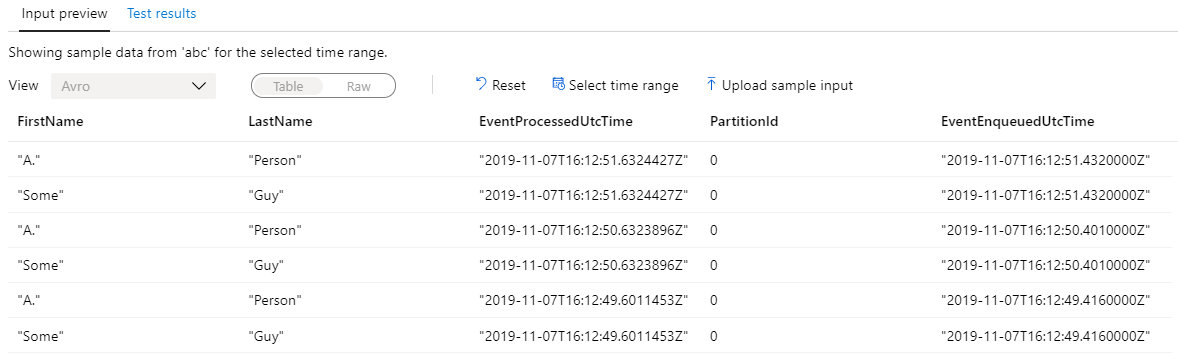
So far so good, but i cannot, for the life of me correctly deserialize this in Databricks leverage the from_avro() command under Scala..
Load (the exact same) schema as a string:
val sampleJsonSchema = dbutils.fs.head("/mnt/schemas/schema.json")
Configure EventHub
val connectionString = ConnectionStringBuilder("<CONNECTION_STRING>")
.setEventHubName("<NAME_OF_EVENT_HUB>")
.build
val eventHubsConf = EventHubsConf(connectionString).setStartingPosition(EventPosition.fromEndOfStream)
val eventhubs = spark.readStream.format("eventhubs").options(eventHubsConf.toMap).load()
Read the data..
// this works, and i can see the serialised data
display(eventhubs.select($"body"))
// this fails, and with an exception: org.apache.spark.SparkException: Malformed records are detected in record parsing. Current parse Mode: FAILFAST. To process malformed records as null result, try setting the option 'mode' as 'PERMISSIVE'.
display(eventhubs.select(from_avro($"body", sampleJsonSchema)))
So essentially, what is going on here.. i am serialising the data with the same schema as deserializing, but something is malformed.. the documentation is incredibly sparse on this front (very very minimal on the Microsoft website).