Second suggestion
(Please read my first suggestion further down for a a few assumptions and conditions)
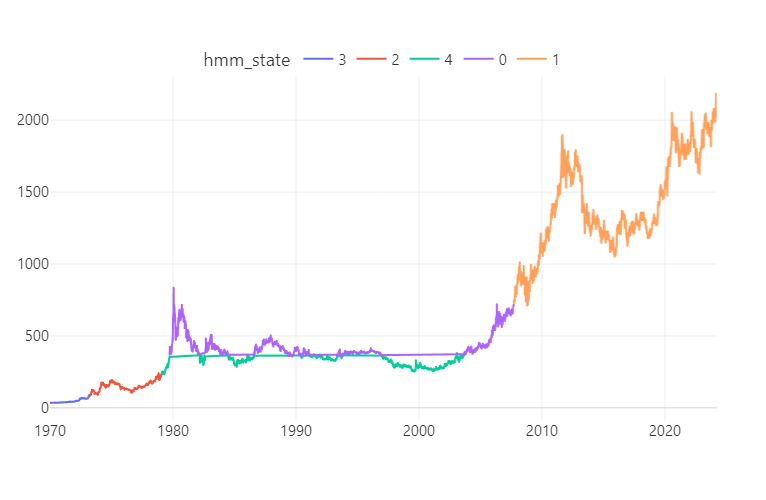
I've managed to build an approach that pretty much should cover all you're asking for here. The only detail that provides a real challenge is how gaps between traces are visualized sinc my second suggestion builds on adding a unique trace for each single label. You may suspect that this would potentially fill the legend with a bunch of duplicate names, but that is taken care of by grouping trace names by the associated label. I've also set up a dictionary where you can specify colors for each label. This is the result:
Plot 2.1 - Color defined by label
![enter image description here]()
Notice the grey line? That's the result of the "connectivity" problem I described earlier. You can chose to hide or show that line by setting the opacity parameter (last number) in color='rgba(200,200,200,0.2)'. You'll find a complete code snippet to reproduce this figure below. There's a lot going on there to tweak this whole thing togeteher, so don't hesitate to ask about the details if anything is unclear.
Complete code:
# imports
import plotly.express as px
import plotly.graph_objects as go
import pandas as pd
import numpy as np
import random
# settings
observations = 100
np.random.seed(5)
value = np.random.uniform(low=-1, high=1, size=observations).tolist()
time = [t for t in pd.date_range('2020', freq='D', periods=observations)]#.format()]
df=pd.DataFrame({'time': time,
'value':value})
df['value']=df['value'].cumsum()
df1 = df.copy()
df1=df1.set_index('time')
# custom function to build labels as conditions of parameter values
def classify(e):
if e > 0.75: return 'high'
if e > 0.25: return 'medium'
if e >= 0: return 'low'
# custom function to set mode = line or marker, given data length
def modes(df):
if len(df) > 1: return 'lines'
else: return 'markers'
# dictionary to specify marker or line color
# this will depend on your real world labels !!!
cols = {'high': 'green',
'medium': 'blue',
'low': 'red'}
df['label1'] = [(elem-df['value'].min())/(df['value'].max()-df['value'].min()) for elem in df['value']]
df['label'] = [classify(elem) for elem in df['label1']]
df = df.drop('label1', 1)
df['group'] = df['label'].ne(df['label'].shift()).cumsum()
df = df.groupby('group')
dfs = []
for name, data in df:
dfs.append(data)
fig = go.Figure()
# one line to connect them all
fig=go.Figure((go.Scatter(x=df1.index, y=df1['value'],
name = 'all data',
line=dict(color='rgba(200,200,200,0.7)'))))
showed = []
for frame in dfs:
if frame['label'].iloc[0] not in showed:
fig.add_trace(go.Scatter(x=frame['time'], y = frame['value'],
mode = modes(frame),
marker_color = cols[frame['label'].iloc[0]],
legendgroup=frame['label'].iloc[0],
name=frame['label'].iloc[0]))
showed.append(frame['label'].iloc[0])
else:
fig.add_trace(go.Scatter(x=frame['time'], y = frame['value'],
mode = modes(frame),
marker_color = cols[frame['label'].iloc[0]],
legendgroup=frame['label'].iloc[0],
name=frame['label'].iloc[0],
showlegend=False
))
fig.update_layout(template='plotly_dark')
fig.update_xaxes(showgrid=False)
fig.update_layout(uirevision='constant')
fig.show()
First suggestion
How you should do this would depend highly on the structure of your dataset. By the sound of your question, I can only guess that it looks something like this:
time param label
0 2020-01-01 -0.556014 medium
1 2020-01-02 0.185451 high
2 2020-01-03 -0.401111 medium
3 2020-01-04 0.436111 high
4 2020-01-05 0.412933 high
5 2020-01-06 0.636421 peak
6 2020-01-07 1.168237 peak
7 2020-01-08 1.205073 peak
8 2020-01-09 0.798674 peak
9 2020-01-10 0.174116 high
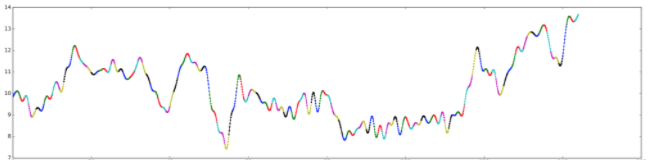
If so, then yon can quickly run into a problem of a weird connectivity between your datapoints if you'd like to display param with a line trace with different colors. The first thing that comes to mind is to combine a line of one color, with markers of multiple colors like this:
![enter image description here]()
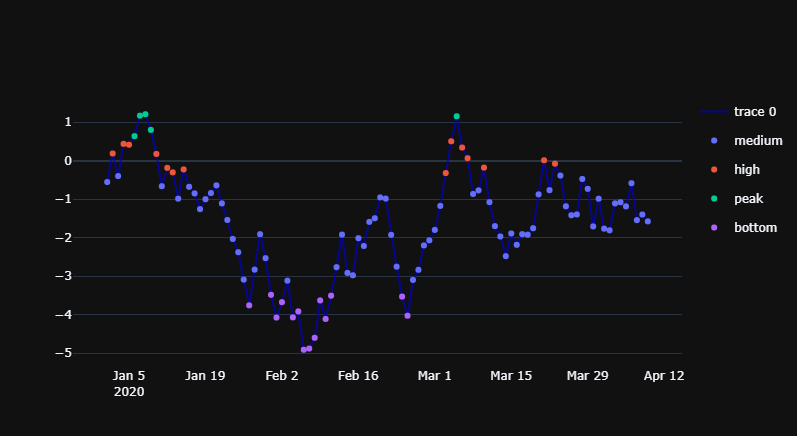
This will give you a nice interactivity where you can switch all elements on and off, perhaps to study only the parts of your data where label=='peak:
![enter image description here]()
Let me know how this works out for you and we can talk some more details. You'll find a data sample and all details here:
Complete code:
# imports
import plotly.express as px
import plotly.graph_objects as go
import pandas as pd
import numpy as np
import random
# settings
observations = 100
np.random.seed(5); cols = list('a')
param = np.random.uniform(low=-1, high=1, size=observations).tolist()
time = [t for t in pd.date_range('2020', freq='D', periods=observations).format()]
df=pd.DataFrame({'time': time,
'param':param})
df['param']=df['param'].cumsum()
def classify(e):
if e > 0.9: return 'peak'
if e > 0.75: return 'high'
if e > 0.25: return 'medium'
if e > 0.9: return 'low'
if e >= 0: return 'bottom'
df['label1'] = [(elem-df['param'].min())/(df['param'].max()-df['param'].min()) for elem in df['param']]
df['label'] = [classify(elem) for elem in df['label1']]
df = df.drop('label1', 1)
fig=go.Figure((go.Scatter(x=df['time'], y=df['param'],
mode='lines',
line=dict(color='rgba(0,0,200,0.7)'))))
fig.add_traces(px.scatter(df, x='time', y='param', color='label').data)
fig.update_layout(template='plotly_dark')
fig.update_xaxes(showgrid=False)
fig.show()