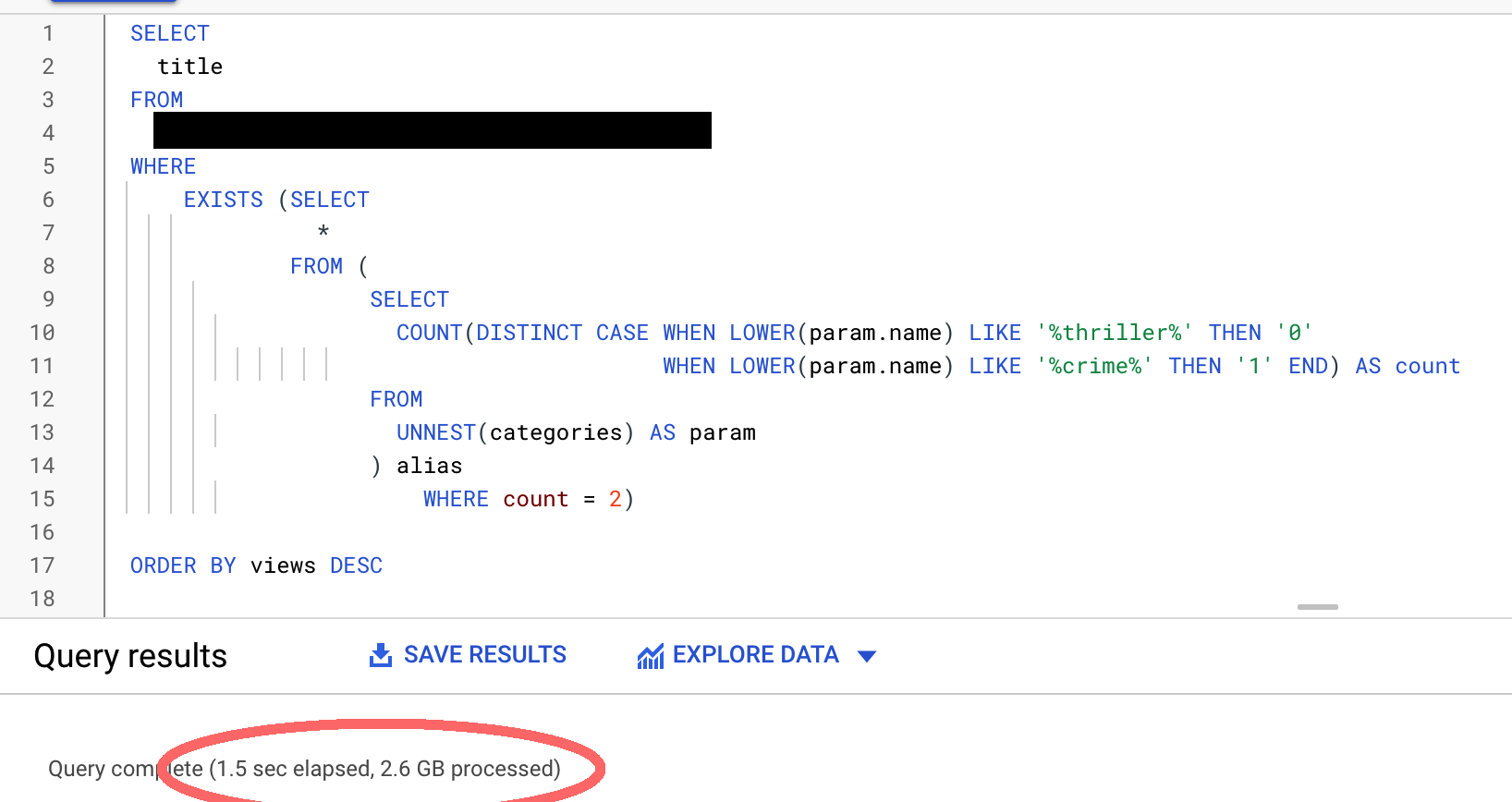
I wanted to migrate from BigQuery to CloudSQL to save cost. My problem is that CloudSQL with PostgreSQL is very very slow compare to BigQuery. A query that takes 1.5 seconds in BigQuery takes almost 4.5 minutes(!) on CloudSQL with PostgreSQL.
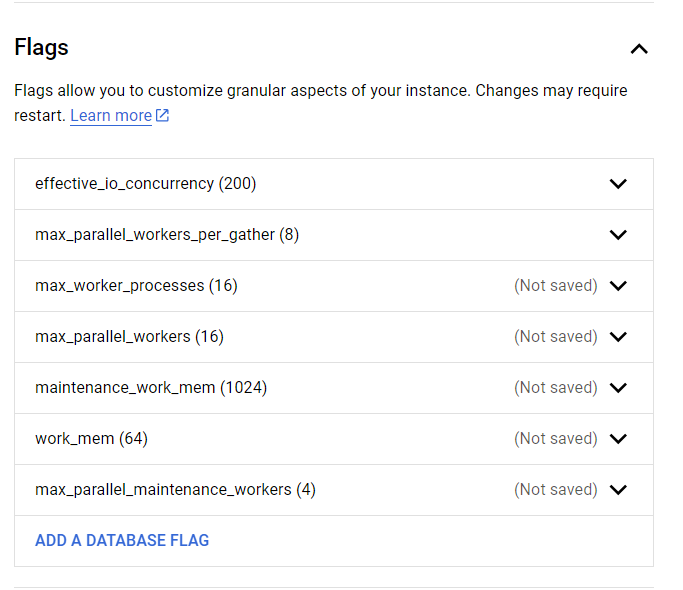
I have CloudSQL with PostgreSQL server with the following configs:

My database have a main table with 16M rows (around 14GB in RAM).
A example query:
EXPLAIN ANALYZE
SELECT
"title"
FROM
public.videos
WHERE
EXISTS (SELECT
*
FROM (
SELECT
COUNT(DISTINCT CASE WHEN LOWER(param) LIKE '%thriller%' THEN '0'
WHEN LOWER(param) LIKE '%crime%' THEN '1' END) AS count
FROM
UNNEST(categories) AS param
) alias
WHERE count = 2)
ORDER BY views DESC
LIMIT 12 OFFSET 0
The table is a videos tables with categories column as text[].
The search condition here looks where there is a categories which is like '%thriller%' and like '%crime%' exactly two times
The EXPLAIN ANALYZE of this query gives this output (CSV): link. The EXPLAIN (BUFFERS) of this query gives this output (CSV): link.
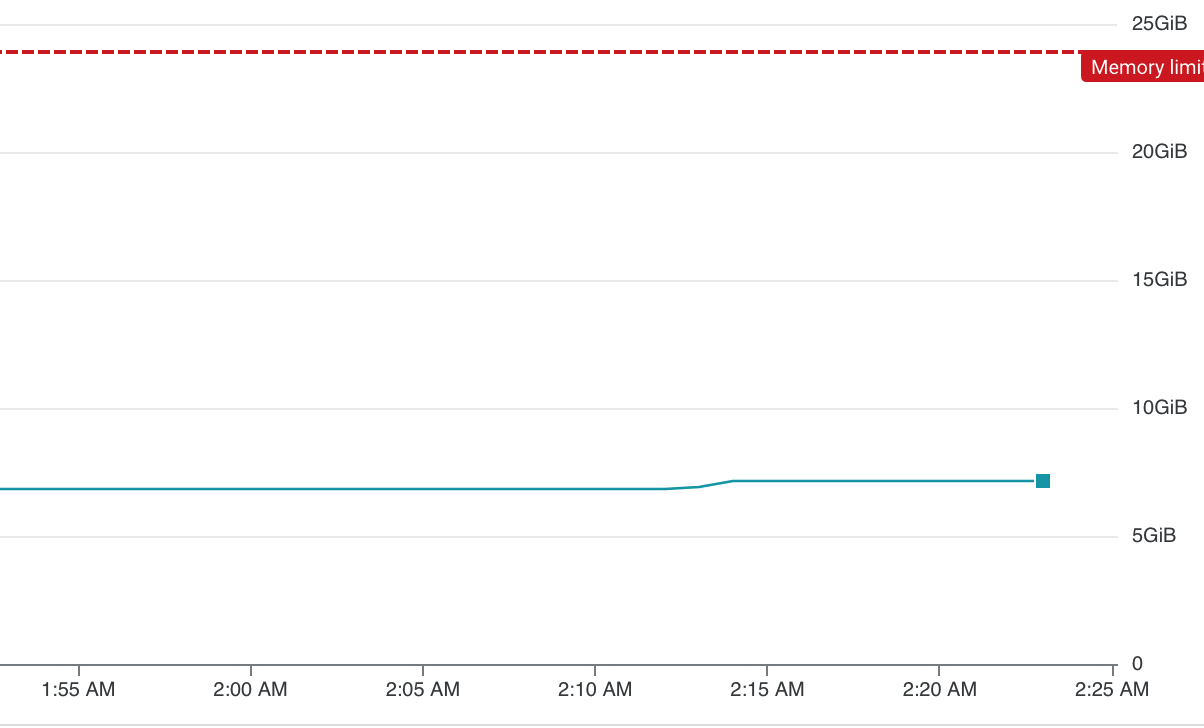
Query Insights graph:

Memory profile:
BigQuery reference for the same query on the same table size:
Server config: link.
Table describe: link.
My goal is to have Cloud SQL with the same query speed as Big Query