I am developing a C++ application, where the program run endlessly, allocating and freeing millions of strings (char*) over time. And RAM usage is a serious consideration in the program. This results in RAM usage getting higher and higher over time. I think the problem is heap fragmentation. And I really need to find a solution.
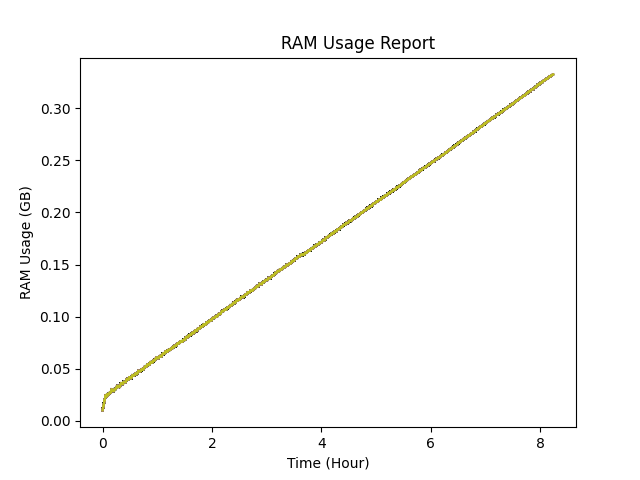
You can see in the image, after millions of allocation and freeing in the program, the usage is just increasing. And the way I am testing it, I know for a fact that the data it stores is not increasing. I can guess that you will ask, "How are you sure of that?", "How are you sure it's not just a memory leak?", Well.
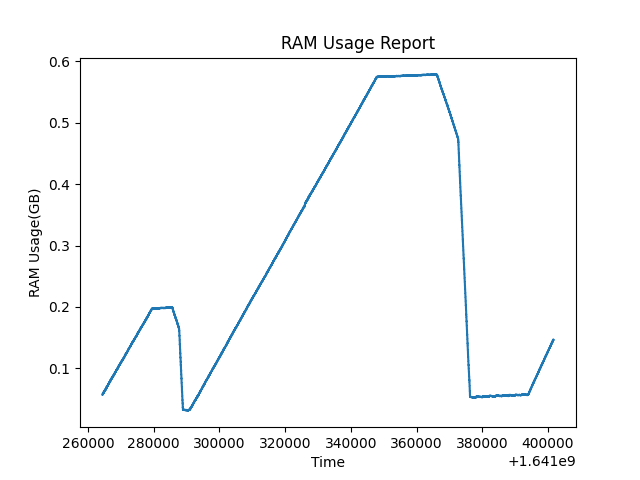
This test run much longer. I run malloc_trim(0), whenever possible in my program. And it seems, application can finally return the unused memory to the OS, and it goes almost to zero (the actual data size my program has currently). This implies the problem is not a memory leak. But I can't rely on this behavior, the allocation and freeing pattern of my program is random, what if it never releases the memory ?
- I said memory pools are a bad idea for this project in the title. Of course I don't have absolute knowledge. But the strings I am allocating can be anything between 30-4000 bytes. Which makes many optimizations and clever ideas much harder. Memory pools are one of them.
- I am using
GCC 11 / G++ 11as a compiler. If some old versions have bad allocators. I shouldn't have that problem. - How am I getting memory usage ? Python
psutilmodule.proc.memory_full_info()[0], which gives meRSS. - Of course, you don't know the details of my program. It is still a valid question, if this is indeed because of heap fragmentation. Well what I can say is, I am keeping a up to date information about how many allocations and frees took place. And I know the element counts of every container in my program. But if you still have some ideas about the causes of the problem, I am open to suggestions.
- I can't just allocate, say 4096 bytes for all the strings so it would become easier to optimize. That's the opposite I am trying to do.
So my question is, what do programmers do(what should I do), in an application where millions of alloc's and free's take place over time, and they are of different sizes so memory pools are hard to use efficiently. I can't change what the program does, I can only change implementation details.
Bounty Edit: When trying to utilize memory pools, isn't it possible to make multiple of them, to the extent that there is a pool for every possible byte count ? For example my strings can be something in between 30-4000 bytes. So couldn't somebody make 4000 - 30 + 1, 3971 memory pools, for each and every possible allocation size of the program. Isn't this applicable ? All pools could start small (no not lose much memory), then enlarge, in a balance between performance and memory. I am not trying to make a use of memory pool's ability to reserve big spaces beforehand. I am just trying to effectively reuse freed space, because of frequent alloc's and free's.
Last edit: It turns out that, the memory growth appearing in the graphs, was actually from a http request queue in my program. I failed to see that hundreds of thousands of tests that I did, bloated this queue (something like webhook). And the reasonable explanation of figure 2 is, I finally get DDOS banned from the server (or can't open a connection anymore for some reason), the queue emptied, and the RAM issue resolved. So anyone reading this question later in the future, consider every possibility. It would have never crossed my mind that it was something like this. Not a memory leak, but an implementation detail. Still I think @Hajo Kirchhoff deserves the bounty, his answer was really enlightening.
charandnew/delete? Have you tried to get some more info with tools such valgrind? – Panekchar*andmalloc/free. – Sauerbratenmallopt, the parameters I played around with as I remember were,M_MXFASTandM_TRIM_THRESHOLD. I will tryM_ARENA_MAX, but setting it to 1, seems to decrease multithread performance, and using a single heap may increase fragmentation rather than decreasing it. – Sauerbratentriein an instant. Unfortunately, they are very different. – Sauerbraten