For example: If the user writes in the Watson Conversation Service:
"I wouldn't want to have a pool in my new house, but I would love to live in a Condo"
How you can know that user doesn't want to have a pool, but he loves to live in a Condo?
For example: If the user writes in the Watson Conversation Service:
"I wouldn't want to have a pool in my new house, but I would love to live in a Condo"
How you can know that user doesn't want to have a pool, but he loves to live in a Condo?
This is a good question and yeah this is a bit tricky...
Currently your best bet is to provide as much examples of the utterances that should be classified as a particular intent as a training examples for that intent - the more examples you provide the more robust the NLU (natural language understanding) will be.
Having said that, note that using examples such as:
"I would want to have a pool in my new house, but I wouldn't love to live in a Condo"
for intent-pool and
"I wouldn't want to have a pool in my new house, but I would love to live in a Condo"
for intent-condo will make the system to correctly classify these sentences, but the confidence difference between these might be quite small (because of the reason they are quite similar when you look just at the text).
So the question here is whether it is worth to make the system classify such intents out-of-the-box or instead train the system on more simple examples and use some form of disambiguation if you see the top N intents have low confidence differences.
Sergio, in this case, you can test all conditions valid with peers node (continue from) and your negative (example else) you can use "true".
Try used the intends for determine the flow and the entities for defining conditions.
See more: https://www.ibm.com/watson/developercloud/doc/conversation/tutorial_basic.shtml
PS: you can get the value of entity using:
This is a typical scenario of multi intents in Conversation service. Everytime user says something, all top 10 intents are identified. You can change your dialog JSON editor like this to see all intents.
{
"output": {
"text": {
"values": [
"<? intents ?>"
],
"selection_policy": "sequential"
}
}
}
For example, When user makes a statement, that will trigger two intents, you'll see that intents[0].confidence and intents[1].confidence both will be pretty high, which means that Conversation identified both the intents from the user text.
But there is a major limitation in it as of now, there is no guaranteed order for the identified intents, i.e. if you have said "I wouldn't want to have a pool in my new house, but I would love to live in a Condo", there is no guarantee that positive intent "would_not_want" will be the intents[0].intent and intent "would_want" will be the intents[1].intent. So it will be a bit hard to implement this scenario with higher accuracy in your application.
This is now easily possible in Watson Assistant. You can do this by creating contextual entities.
In your intent, you mark the related entity and flag it to the entity you define. The contextual entities will now learn the structure of the sentence. This will not only understand what you have flagged, but also detect entities you haven't flagged.
So example below ingredients have been tagged as wanted and not wanted.
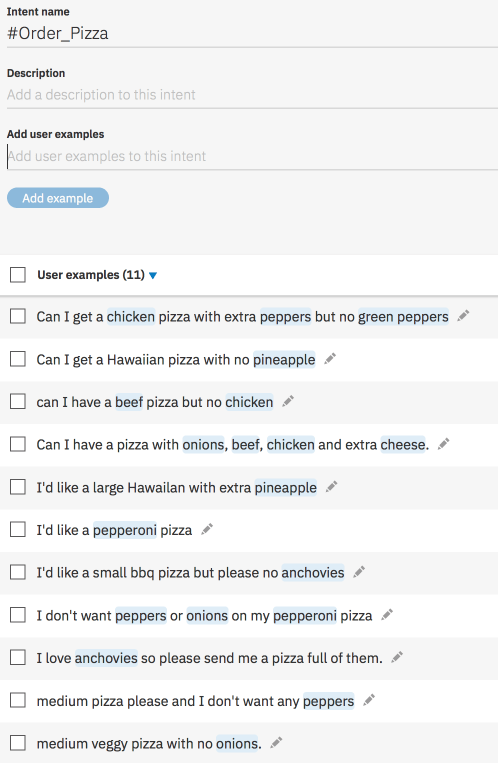
When you run it you get this.
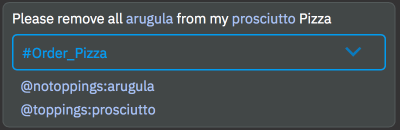
Full example here: https://sodoherty.ai/2018/07/24/negation-annotation/
© 2022 - 2024 — McMap. All rights reserved.