An image is worth a thousand words:
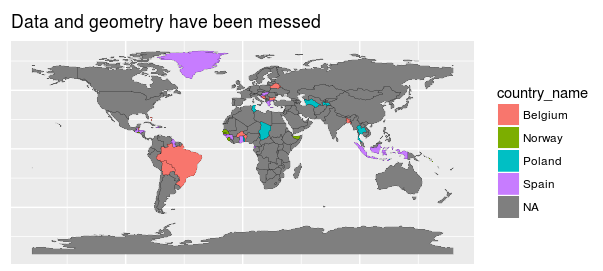
Observed behaviour: As can be seen from the image above, countries' names do not match with their actual geometries.
Expected behaviour: I would like to properly join a data frame with its geometry and display the result in ggmap.
I've previously joined different data frames, but things get wrong by the fact that apparently ggmap needs to "fortify" (actually I don't know what really means) data frame in order to display results.
This is what I've done so far:
library(rgdal)
library(dplyr)
library(broom)
library(ggmap)
# Load GeoJSON file with countries.
countries = readOGR(dsn = "https://gist.githubusercontent.com/ccamara/fc26d8bb7e777488b446fbaad1e6ea63/raw/a6f69b6c3b4a75b02858e966b9d36c85982cbd32/countries.geojson")
# Load dataframe.
df = read.csv("https://gist.githubusercontent.com/ccamara/fc26d8bb7e777488b446fbaad1e6ea63/raw/a6f69b6c3b4a75b02858e966b9d36c85982cbd32/sample-dataframe.csv")
# Join geometry with dataframe.
countries$iso_a2 = as.factor(countries$iso_a2)
countries@data = left_join(countries@data, df, by = c('iso_a2' = 'country_code'))
# Convert to dataframe so it can be used by ggmap.
countries.t = tidy(countries)
# Here's where the problem starts, as by doing so, data has been lost!
# Recover attributes' table that was destroyed after using broom::tidy.
countries@data$id = rownames(countries@data) # Adding a new id variable.
countries.t = left_join(countries.t, countries@data, by = "id")
ggplot(data = countries.t,
aes(long, lat, fill = country_name, group = group)) +
geom_polygon() +
geom_path(colour="black", lwd=0.05) + # polygon borders
coord_equal() +
ggtitle("Data and geometry have been messed!") +
theme(axis.text = element_blank(), # change the theme options
axis.title = element_blank(), # remove axis titles
axis.ticks = element_blank()) # remove axis ticks
?broom::tidy): It seems to me that the statementcountries.t = tidy(countries, region = "name")is key in your answer, but I do not understand whatregion="name"exactly does, despite I have observed notable differences in the output if I just typecountries.t = tidy(countries)– Spurlock