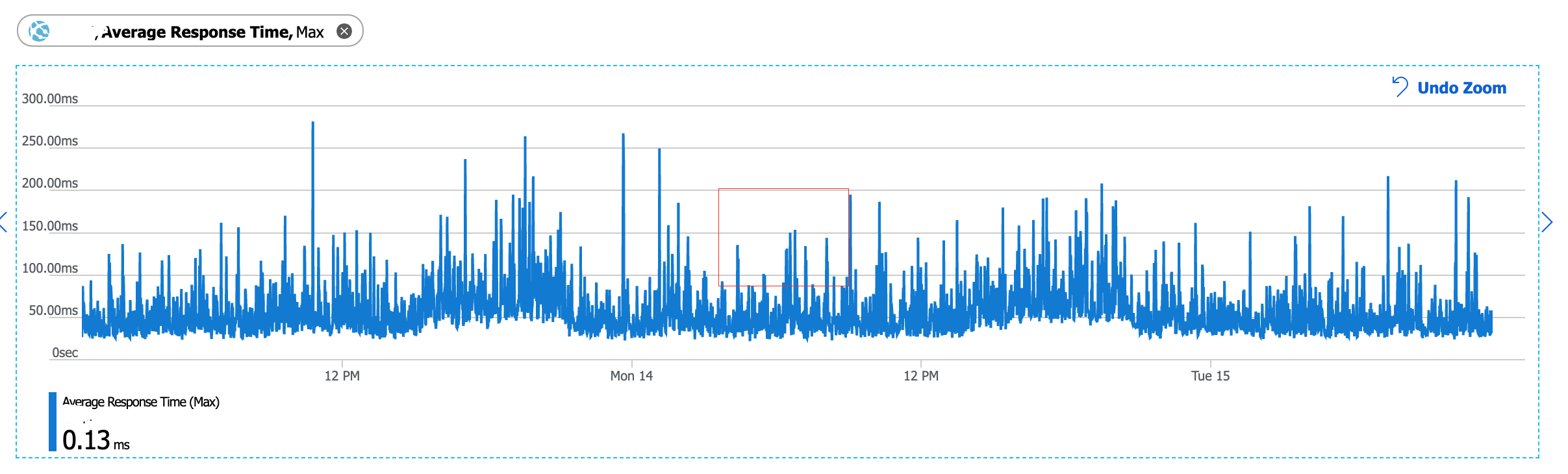
We have a production system which is an ASP.NET Web API (classic, not .NET Core) application published to Azure. Data storage is Azure SQL Database and we use Entity Framework to access the data. API has a medium load, 10-60 requests per second and upper_90 latency is 100-200 ms which is a target latency is our case. Some time ago we noticed that approximately every 20-30 minutes our services stalls and latency jumps to approximately 5-10 sec. All requests start to be slow for about a minute and then the system recovers by itself. Same time no requests are being dropped, they all just take longer to execute. for a short period of time (usually 1 minute).
We start to see the following picture at our HTTP requests telemetry (Azure):
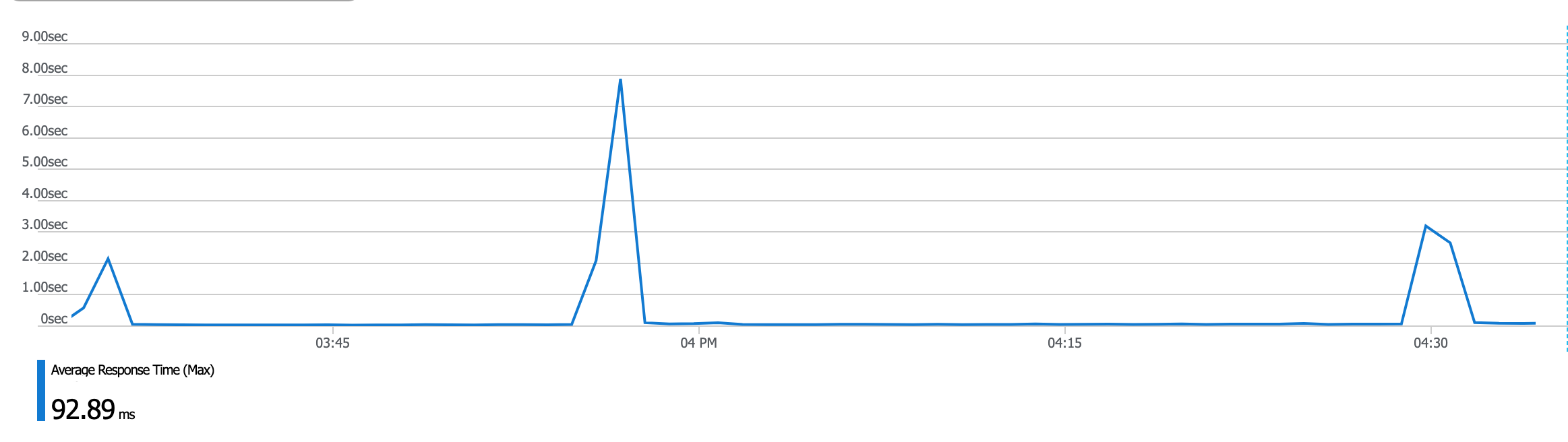
We can also see a correlation to with our Azure SQL Database metrics, such as DTU (drop) and connections (increase):
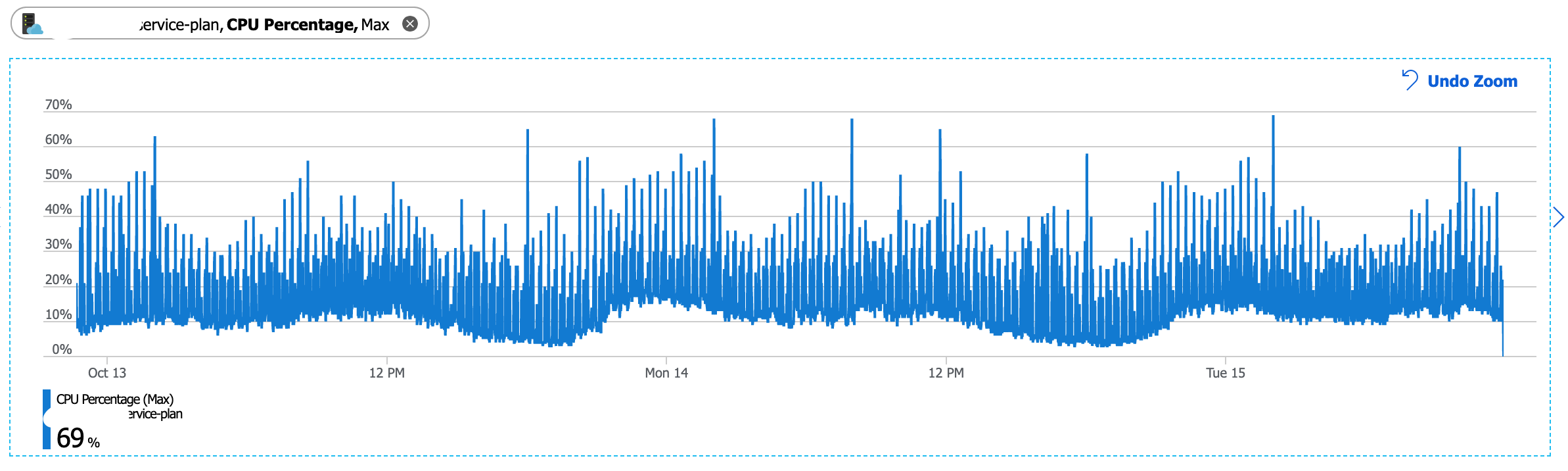
We've analyzed the server and didn't see any correlation with the host (we have just one host) CPU/Memory usage, it's stable at 20-30% CPU usage level and 50% memory usage.
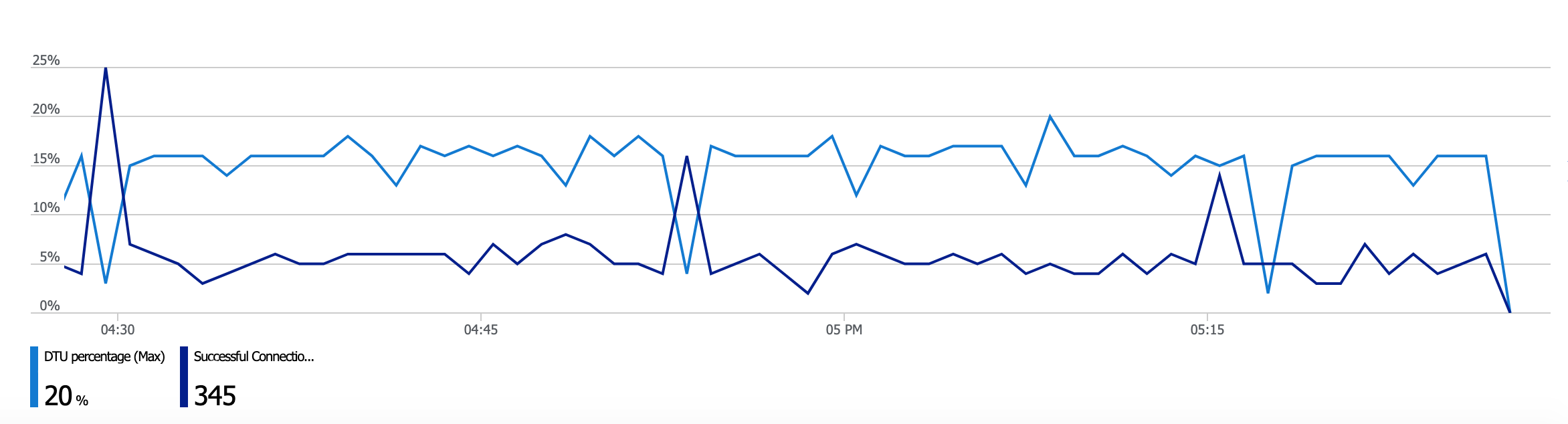
We also have an alternative source of telemetry which shows the same behavior. Our telemetry measures API latency and database metrics such as active connection count and pooled connection count (ADO.NET Connection Pool):
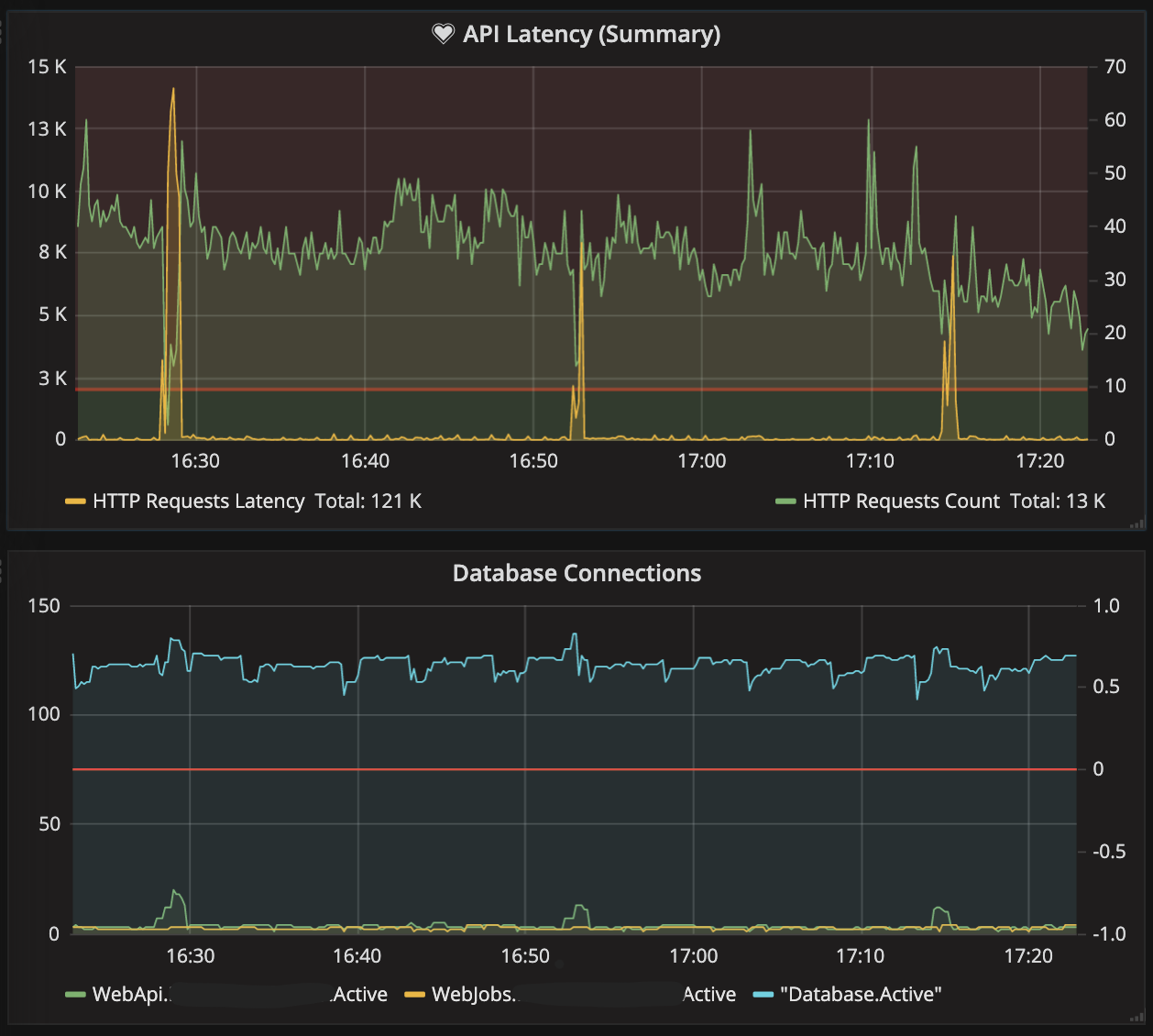
What is interesting, that every system stall is accompanied by a pooled connection quantity raise. And our tests show, the more connection pooled, the longer you spend waiting on a new connection from that pool to execute your next database operation. We analyzed a few suggestions but were unable to prove or disprove any of them:
- ADO.NET connection leak (all our db access happens in a using statement with proper connection disposal/return to pool)
- Socket/Port Exhaustion - where unable to properly track telemetry on that metric
- CPU/Memory bottleneck - charts shows there is none
- DTU (database units) bottleneck - charts shows there is none
As of now we are trying to identify the possible culprit of this behavior. Unfortunately, we cannot identify the changes which led to it becuase of missing telemetry, so now the only way to deal with the issue is to properly diagnose it. And, of course, we can only reproduce it in production, under permanent load (even when load is not high like 10 requests a second).
What are the possible causes for this behavior and what is the proper way to diagnose and troubleshoot it?