I have a sort of ELK stack, with fluentd instead of logstash, running as a DaemonSet on a Kubernetes cluster and sending all logs from all containers, in logstash format, to an Elasticsearch server.
Out of the many containers running on the Kubernetes cluster some are nginx containers which output logs of the following format:
121.29.251.188 - [16/Feb/2017:09:31:35 +0000] host="subdomain.site.com" req="GET /data/schedule/update?date=2017-03-01&type=monthly&blocked=0 HTTP/1.1" status=200 body_bytes=4433 referer="https://subdomain.site.com/schedule/2589959/edit?location=23092&return=monthly" user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0" time=0.130 hostname=webapp-3188232752-ly36o
The fields visible in Kibana are as per this screenshot:
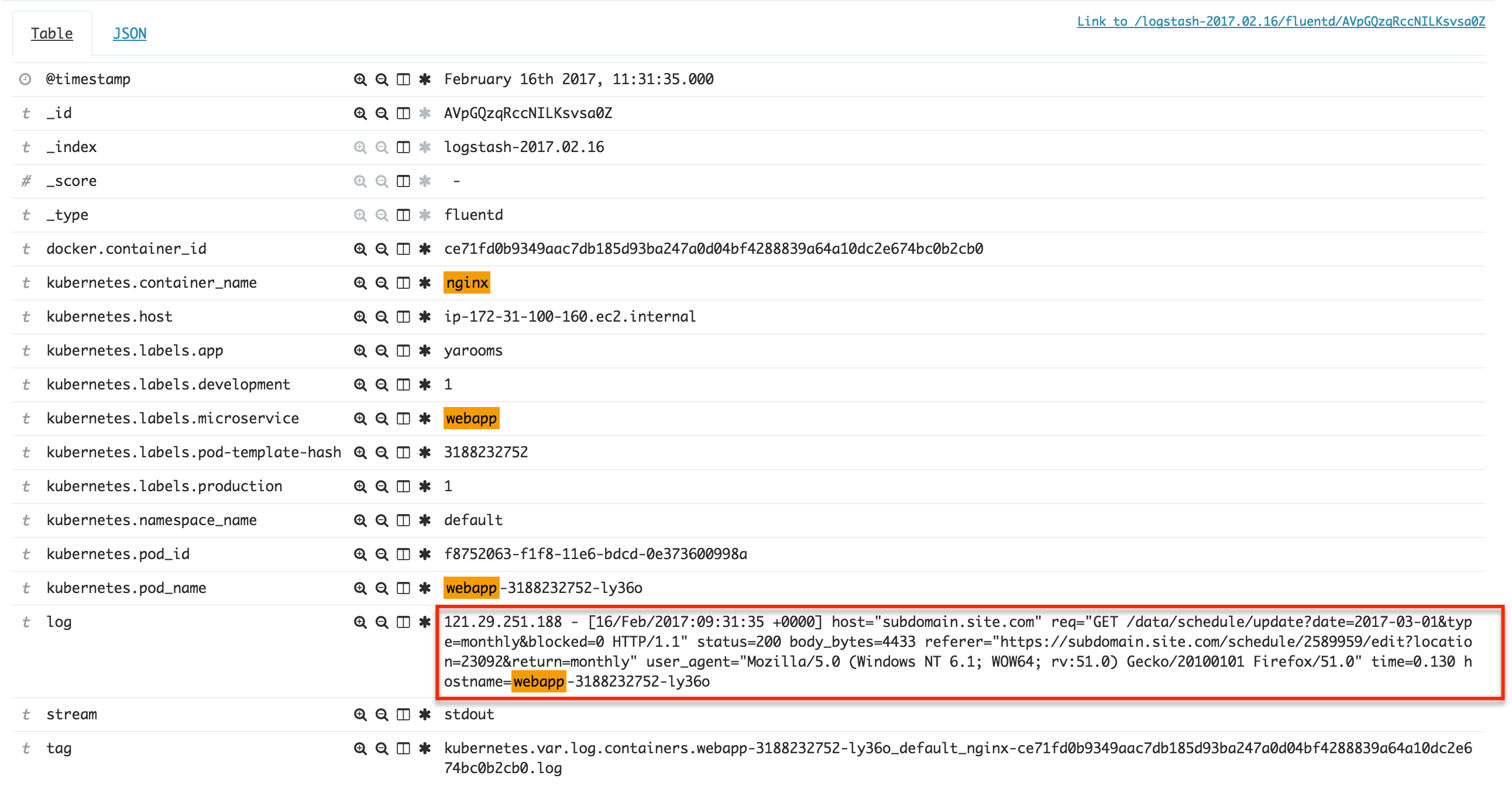
Is it possible to extract fields from this type of log after it was indexed?
The fluentd collector is configured with the following source, which handles all containers, so enforcing a format at this stage is not possible due to the very different outputs from different containers:
<source>
type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag kubernetes.*
format json
read_from_head true
</source>
In an ideal situation, I would like to enrich the fields visible in the screenshot above with the meta-fields in the "log" field, like "host", "req", "status" etc.