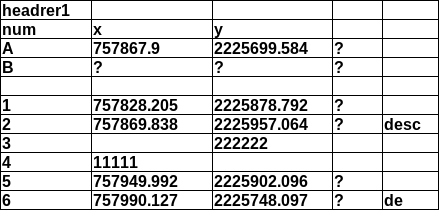
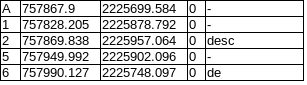
solution
import string
import pandas
def pandas_clean_csv(csv_file):
"""
Function pandas_clean_csv Documentation
- I Got help from this site, it's may help you as well:
Get the row with the largest number of missing data for more Documentation
https://moonbooks.org/Articles/How-to-filter-missing-data-NAN-or-NULL-values-in-a-pandas-DataFrame-/
"""
try:
if not csv_file.endswith('.csv'):
raise TypeError("Be sure you select .csv file")
# get punctuations marks as list !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
punctuations_list = [mark for mark in string.punctuation]
# import csv file and read it by pandas
data_frame = pandas.read_csv(
filepath_or_buffer=csv_file,
header=None,
skip_blank_lines=True,
error_bad_lines=True,
encoding='utf8',
na_values=punctuations_list
)
# if elevation column is NaN convert it to 0
data_frame[3] = data_frame.iloc[:, [3]].fillna(0)
# if Description column is NaN convert it to -
data_frame[4] = data_frame.iloc[:, [4]].fillna('-')
# select coordinates columns
coord_columns = data_frame.iloc[:, [1, 2]]
# convert coordinates columns to numeric type
coord_columns = coord_columns.apply(pandas.to_numeric, errors='coerce', axis=1)
# Find rows with missing data
index_with_nan = coord_columns.index[coord_columns.isnull().any(axis=1)]
# Remove rows with missing data
data_frame.drop(index_with_nan, 0, inplace=True)
# iterate data frame as tuple data
output_clean_csv = data_frame.itertuples(index=False)
return output_clean_csv
except Exception as E:
print(f"Error: {E}")
exit(1)
out_data = pandas_clean_csv('csv_files/version2_bad_headers.csl')
for i in out_data:
print(i[0], i[1], i[2], i[3], i[4])
Here you can Download my test CSV files