I am trying to create a table using values from an ecdf plot. I've recreated an example below.
#Data data(mtcars) #Sort by mpg mtcars <- mtcars[order(mtcars$mpg),] #Make arbitrary ranking variable based on mpg mtcars <- mtcars %>% mutate(Rank = dense_rank(mpg)) #Make variable for percent picked mtcars <- mutate(mtcars, Percent_Picked = Rank/max(mtcars$Rank)) #Make cyl categorical mtcars$cyl<-cut(mtcars$cyl, c(3,5,7,9), right=FALSE, labels=c(4,6,8)) #Make the graph ggplot(mtcars, aes(Percent_Picked, color = cyl)) + stat_ecdf(size=1) + scale_x_continuous(labels = scales::percent) + scale_y_continuous(labels = scales::percent)
Which creates this plot 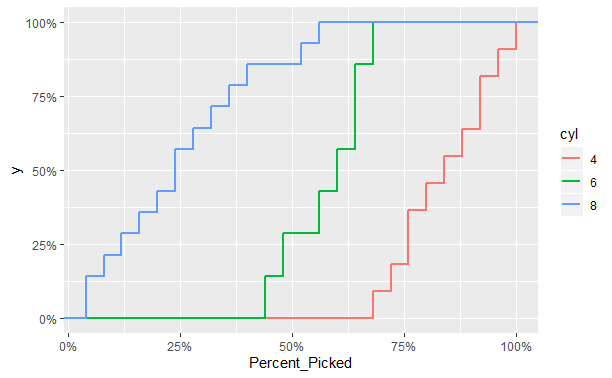
I want to create a table for the value of each of the cylinder types when the overall Percent_Picked is at 25%, 50%, and 75%. So something that shows that 4-cylander is at 0%, 6 is around 28%, and 8 is around 85%.
Calculating quantiles by group doesn't give me what I want (it shows the percent of all cylinders picked when 25%, 50%, and 75% of the particular cylinder type was picked). (For example, the suggestions by tbradley1013 on their blog only help with quantiles for each particular cylinder, not the overall cdf for each cylinder at given quantiles for Percent_Picked.)
Any leads would be appreciated!