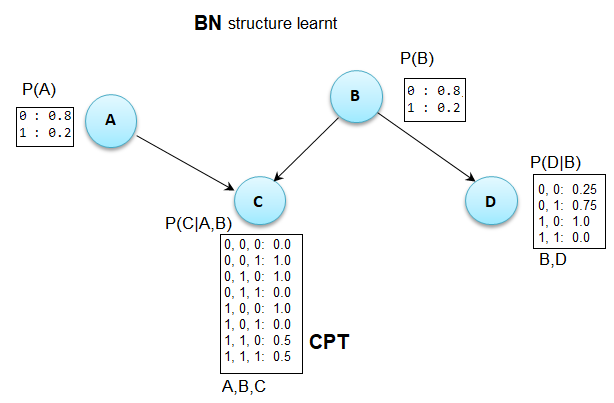
Just to elucidate the above answers with a concrete example, so that it will be helpful for someone, let's start with the following simple dataset (with 4 variables and 5 data points):
import pandas as pd
df = pd.DataFrame({'A':[0,0,0,1,0], 'B':[0,0,1,0,0], 'C':[1,1,0,0,1], 'D':[0,1,0,1,1]})
df.head()
# A B C D
#0 0 0 1 0
#1 0 0 1 1
#2 0 1 0 0
#3 1 0 0 1
#4 0 0 1 1
Now let's learn the Bayesian Network structure from the above data using the 'exact' algorithm with pomegranate (uses DP/A* to learn the optimal BN structure), using the following code snippet
import numpy as np
from pomegranate.bayesian_network import *
model = BayesianNetwork.from_samples(df.to_numpy(), state_names=df.columns.values, algorithm='exact')
# model.plot()
The BN structure that is learn is shown in the next figure along with the corresponding CPTs
![enter image description here]()
As can be seen from the above figure, it explains the data exactly. We can compute the log-likelihood of the data with the model as follows:
np.sum(model.log_probability(df.to_numpy()))
# -7.253364813857112
Once the BN structure is learnt, we can sample from the BN as follows:
model.sample()
# array([[0, 1, 0, 0]], dtype=int64)
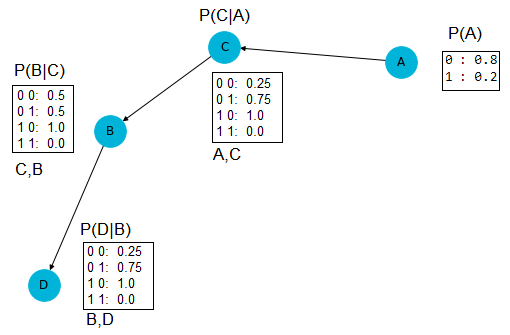
As a side note, if we use algorithm='chow-liu' instead (which finds a tree-like structure with fast approximation), we shall obtain the following BN:
![enter image description here]()
The log-likelihood of the data this time is
np.sum(model.log_probability(df.to_numpy()))
# -8.386987635761297
which indicates the algorithm exact finds better estimate.