By SQL Server's documentation (and legacy documentation), a nvarchar field without _SC collation, should use the UCS-2 ENCODING.
Starting with SQL Server 2012 (11.x), when a Supplementary Character (SC) enabled collation is used, these data types store the full range of Unicode character data and use the UTF-16 character encoding. If a non-SC collation is specified, then these data types store only the subset of character data supported by the UCS-2 character encoding.
It also states that the UCS-2 ENCODING stores only the subset characters supported by UCS-2. From wikipedia UCS-2 specification:
UCS-2, uses a single code value [...] between 0 and 65,535 for each character, and allows exactly two bytes (one 16-bit word) to represent that value. UCS-2 thereby permits a binary representation of every code point in the BMP that represents a character. UCS-2 cannot represent code points outside the BMP.
So, by the specifications above, seems that I won't be able to store a emoji like: 😍 which have a value of 0x1F60D (or 128525 in decimal, way above 65535 limit of UCS-2). But on SQL Server 2008 R2 or SQL Server 2019 (both with the default SQL_Latin1_General_CP1_CI_AS COLLATION), on a nvarchar field, it's perfectly stored and returned (although not supported on comparisons with LIKE or =):
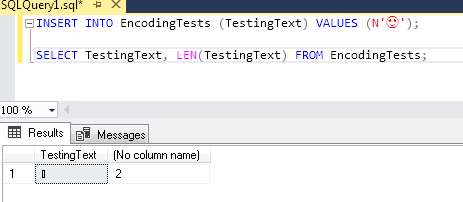
SMSS doesn't render emoji correctly, but here is the value copied and pasted from query result: 😍
So my questions are:
Is
nvarcharfield really usingUSC-2on SQL Server 2008 R2 (I also tested on SQL Server 2019, with same non_SCcollations and got same results)?Is Microsoft's documentation of
nchar/nvarcharmisleading about "then these data types store only the subset of character data supported by the UCS-2 character encoding"?Does
UCS-2ENCODINGsupport or not code points beyond 65535?How SQL Server was able to correctly store and retrieve this field's data, when it's outside the support of
UCS-2ENCODING?
NOTE: Server's Collation is SQL_Latin1_General_CP1_CI_AS and Field's Collation is Latin1_General_CS_AS.
NOTE 2: The original question stated tests about SQL Server 2008. I tested and got same results on a SQL Server 2019, with same respective COLLATIONs.
NOTE 3: Every other character I tested, outside UCS-2 supported range, is behaving on the same way. Some are: 𝕂, 😂, 𨭎, 𝕬, 𝓰