This is the code client-side, it's a minimum, complete and verifiable snippet that will allow fellow developers to test this by themselves.
// requires: a string that contains html tags
// returns: a word document that can be downloaded with extension .doc or docx
// @ param cvAsHTML is a string that contains html tags
const preHtml = "<html xmlns:v='urn:schemas-microsoft-com:vml' xmlns:o='urn:schemas-microsoft-com:office:office' xmlns:w='urn:schemas-microsoft-com:office:word' xmlns='http://www.w3.org/TR/html4/loose.dtd\'><head><meta charset='utf-8'></head><body>";
const postHtml = "</body></html>";
const html = preHtml + cvAsHTML + postHtml;
let filename = "filename";
const blob = new Blob(["\ufeff", html], { type: "application/msword"});
The above snippet works like a charm. Please note that the XML schemas are redundant and actually unnecessary. The doc file would work without them but head and body tags must be present.
For docx files I am unable to download the file. The file appears to be corrupted and after several trials I really do not know what to do. This is the code for docx files:
const preHtml = "<?xml version='1.0' encoding='UTF-8?><html xmlns:v='urn:schemas-microsoft-com:vml' xmlns:o='urn:schemas-microsoft-com:office:office' xmlns:w='urn:schemas-microsoft-com:office:word' xmlns='http://www.w3.org/TR/html4/loose.dtd\'><head><meta charset='utf-8'></head><body>";
const postHtml = "</body></html>";
const html = preHtml + cvAsHTML + postHtml;
let filename = "filename.docx";
const blob = new Blob(["\ufeff", html], { type: "application/vnd.openxmlformats-officedocument.wordprocessingml.document.main"});
Note: I have changed the MIME type inside the Blob object and tried different other options as well such as application/zip, application/octet-stream etc. with no avail. I have also changed the prehtml variable to include:
<?xml version='1.0' encoding='UTF-8?>
Given I understand that docx files are essentially zipped files containing xml segments...
Would really appreciate any help given.
EDIT: 16-Dec-2019
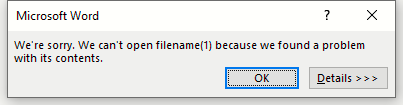
This is the screenshot I took after the implementation suggested by @dw_:
The implementation using JSZip does not work as expected since:
- The browser does not natively allow the user to open the file in microsoft word, like it does with
docfiles; - Users must save the file first but even then, the file won't open since it is corrupted.
docformat the browser natively support the "save file with microsoft word" and I can open the file directly without going for the save option. Try running your own snippet and you will see the browser does not let you save the file in docx nor does it let you open (read) the file like it does withdocfiles. – Kistna