TL;DR
The transactional id is for preventing duplicates caused by zombie processes in the read-process-write pattern where you read from and produce to kafka topics. For request oriented applications, e.g. messages being produced by an incoming http request, transactional id doesn't bring any benefit (of course you still need to assign one if you want to use transactions and shouldn't be repeated between producers in the same process or different processes in your cluster)
Long answer
As the docs say, transactional producers are not thread safe
As is hinted at in the example, there can be only one open transaction per producer. All messages sent between the beginTransaction() and commitTransaction() calls will be part of a single transaction
so as you correctly explained there can't be concurrent access to the producer so we must pick one of the three options you described.
For this answer I'm going to assume that request oriented applications corresponds to http requests as the mechanism is triggering a message being produced with a transaction (actually, more than one message, otherwise will be enough with idempotent producers and transactions won't be needed)
In terms of correctness all of them are ok as, option 1 would work but depending on your application throughput it could have a high contention, option 2 will also work but you will pay the price of a higher latency and won't be very efficient.
IMHO I think option 3 could be the best since is a compromise between of the two previous options, although of course requires a more careful implementation than just opening a new producer each time.
Transactional id
The question that remains is how to assign a transactional id to the producer, specially in the last case (although both options 1 and 3 share the same concern, since in both cases we are reusing a producer with the same transactional id to handle different requests).
To answer this we first need to understand that the goal of transactional.id is to protect us from having duplicate message being produced caused by zombie processes (a process that hangs for a while, e.g. bc of a long gc pause, and is considered dead but after a while comes back and continues), this is called zombie fencing.
An important detail to understand the need of zombie fencing is understanding in which use case it could happen and this is the read-process-write pattern where you read from a topic, process the element and write to an output topic and the offset topic, which give us atomicity and Exactly-once semantics (if you are not doing any side effects on the process step).
Idempotent producers prevent us from having duplicates caused by producer retries (where the message was persisted by the broker but the ack wasn't received by the producer) and two-phase commit within kafka (where we are not only writing to the output but also marked the message as consumed by also producing to the offset topic) prevent us from having duplicates caused by consuming the message more than once (if the process crashes after producing to the output topic but before committing the offset).
There is still a subtle case where a duplicate can be introduced and it is a zombie producer, which is fenced by monotonically increasing an epoch each time a producer calls initTransactions that will be send with every message the producer sends.
So, for a producer to be fenced, another producer should have being started with the same transaction id, the key here is explained by Jason Gustafson in this talk
"what we are looking for is a guarantee that for each input partition there is only a single write that is responsible for reading that data and writing the output"
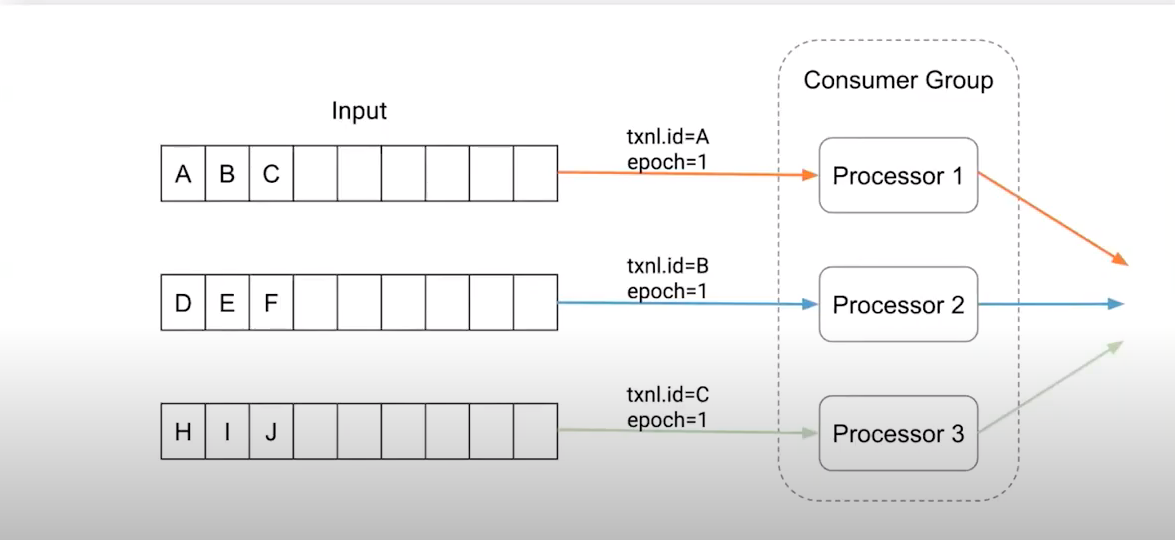
This means the transactional.id is assigned in terms of the partition is being consumed in the "read-process-write" pattern.
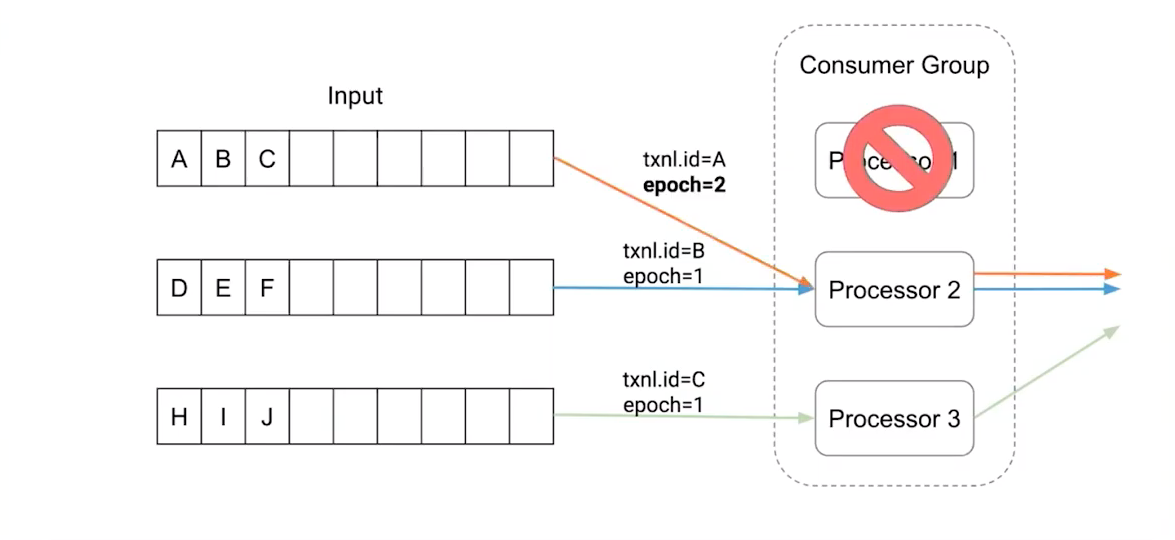
So if a process that has assigned partition 0 of topic A is considered dead, a rebalance will kick off and the new process that is assigned should create a producer with the same transactional.id, that's why it should be something like this <prefix><group>.<topic>.<partition> as described in this answer, where the partition is part of the transactional.id. This also means a producer per partition assigned, which could also represent an overhead depending on how many topics and partitions your consumers are being assigned.
This slides from the talk clarifies this situation
Transactional id before process crash
![transactional id before process crash]()
Transactional id reassigned to other process after crash
![enter image description here]()
Transactional id in http requests
Going back to your original question, http requests won't follow the read-process-write pattern where zombies can introduce duplicates, because each http request will be unique, even if you introduce a unique identifier it will be a different message from the point of view of the transactional producer.
In this case I would argue that you may still have value using the transactional producer if you want the atomicity of writing to two different topics, but you can choose a random transactional id for option 2, or reuse it for options 1 and 3.
UPDATE
My answer is outdated since is based in an old version of kafka.
The overhead of having one producer per partition described before was a concern that was tackled in KIP-447
This architecture does not scale well as the number of input partitions increases. Every producer come with separate memory buffers, a separate thread, separate network connections. This limits the performance of the producer since we cannot effectively use the output of multiple tasks to improve batching. It also causes unneeded load on brokers since there are more concurrent transactions and more redundant metadata management.
This is the main difference as explained in this post
When the partition assignment is finalized after a consumer group rebalance, the first step for the consumer is to always get the next offset to begin fetching data. With this observation, the OffsetFetch protocol protection is enhanced, such that when a consumer group has pending transactional offsets associated with one partition, the OffsetFetch call can be blocked until the associated transaction completes. Previously, the “outdated” offset data would be returned and the application allowed to continue immediately.
Whit this new feature, the use of transactional.id is no longer clear to me.
Although it is still unclear why fencing requires both blocking the poll if there are pending transactions while it seems to me that the sending the consumer group metadata should be enough (I assume a zombie producer will be fenced by commiting with an old generation.id for that group.id, the generation.id being bumped with each rebalance) it seems the transactional.id doesn't play a major role anymore. e.g. spring docs says
With mode V1, the producer is "fenced" if another instance with the same transactional.id is started. Spring manages this by using a Producer for each group.id/topic/partition; when a rebalance occurs a new instance will use the same transactional.id and the old producer is fenced.
With mode V2, it is not necessary to have a producer for each group.id/topic/partition because consumer metadata is sent along with the offsets to the transaction and the broker can determine if the producer is fenced using that information instead.