SHORT ANSWERS
Is the above assumption correct or am I thinking wrong way??
In short, yes you are thinking the wrong way. Read my loooong explanation with example to understand why, hope you will appreciate it.
Also, I have created a 2nd Batch step, to capture ONLY FAILEDRECORDS.
But, with the current Design, I am not able to Capture failed records.
You probably forget to set max-failed-records = "-1" (unlimited) on batch job. Default is 0, on first failed record batch will return and not execute subsequent steps.
Is, the approach I am using is it fine, or any better Design can be
followed??
I think it makes sense if performance is essential for you and you can't cope with the overhead created by doing this operation in sequence.
If instead you can slow down a bit it could make sense to do this operation in 5 different steps, you will loose parallelism but you can have a better control on failing records especially if using batch commit.
MULE BATCH JOB IN PRACTICE
I think the best way to explain how it works it trough an example.
Take in consideration the following case:
You have a batch processing configured with max-failed-records = "-1" (no limit).
<batch:job name="batch_testBatch" max-failed-records="-1">
In this process we input a collection composed by 6 strings.
<batch:input>
<set-payload value="#[['record1','record2','record3','record4','record5','record6']]" doc:name="Set Payload"/>
</batch:input>
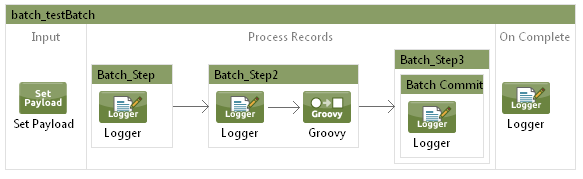
The processing is composed by 3 steps"
The first step is just a logging of the processing and the second step will instead do a logging and throw an exception on record3 to simulate a failure.
<batch:step name="Batch_Step">
<logger message="-- processing #[payload] in step 1 --" level="INFO" doc:name="Logger"/>
</batch:step>
<batch:step name="Batch_Step2">
<logger message="-- processing #[payload] in step 2 --" level="INFO" doc:name="Logger"/>
<scripting:transformer doc:name="Groovy">
<scripting:script engine="Groovy"><![CDATA[
if(payload=="record3"){
throw new java.lang.Exception();
}
payload;
]]>
</scripting:script>
</scripting:transformer>
</batch:step>
The third step will instead contain just the commit with a commit count value of 2.
<batch:step name="Batch_Step3">
<batch:commit size="2" doc:name="Batch Commit">
<logger message="-- committing #[payload] --" level="INFO" doc:name="Logger"/>
</batch:commit>
</batch:step>
Now you can follow me in the execution of this batch processing:
![enter image description here]()
On start all 6 records will be processed by the first step and logging in console would look like this:
-- processing record1 in step 1 --
-- processing record2 in step 1 --
-- processing record3 in step 1 --
-- processing record4 in step 1 --
-- processing record5 in step 1 --
-- processing record6 in step 1 --
Step Batch_Step finished processing all records for instance d8660590-ca74-11e5-ab57-6cd020524153 of job batch_testBatch
Now things would be more interesting on step 2 the record 3 will fail because we explicitly throw an exception but despite this the step will continue in processing the other records, here how the log would look like.
-- processing record1 in step 2 --
-- processing record2 in step 2 --
-- processing record3 in step 2 --
com.mulesoft.module.batch.DefaultBatchStep: Found exception processing record on step ...
Stacktrace
....
-- processing record4 in step 2 --
-- processing record5 in step 2 --
-- processing record6 in step 2 --
Step Batch_Step2 finished processing all records for instance d8660590-ca74-11e5-ab57-6cd020524153 of job batch_testBatch
At this point despite a failed record in this step batch processing will continue because the parameter max-failed-records is set to -1 (unlimited) and not to the default value of 0.
At this point all the successful records will be passed to step3, this because, by default, the accept-policy parameter of a step is set to NO_FAILURES. (Other possible values are ALL and ONLY_FAILURES).
Now the step3 that contains the commit phase with a count equal to 2 will commit the records two by two:
-- committing [record1, record2] --
-- committing [record4, record5] --
Step: Step Batch_Step3 finished processing all records for instance d8660590-ca74-11e5-ab57-6cd020524153 of job batch_testBatch
-- committing [record6] --
As you can see this confirms that record3 that was in failure was not passed to the next step and therefore not committed.
Starting from this example I think you can imagine and test more complex scenario, for example after commit you could have another step that process only failed records for make aware administrator with a mail of the failure.
After you can always use external storage to store more advanced info about your records as you can read in my answer to this other question.
Hope this helps