I'm trying to use TensorFlow with my deep learning project.
Here I need implement my gradient update in this formula :
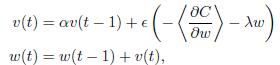
I have also implement this part in Theano, and it came out the expected answer. But when I try to use TensorFlow's MomentumOptimizer, the result is really bad. I don't know what is different between them.
Theano:
def gradient_updates_momentum_L2(cost, params, learning_rate, momentum, weight_cost_strength):
# Make sure momentum is a sane value
assert momentum < 1 and momentum >= 0
# List of update steps for each parameter
updates = []
# Just gradient descent on cost
for param in params:
param_update = theano.shared(param.get_value()*0., broadcastable=param.broadcastable)
updates.append((param, param - learning_rate*(param_update + weight_cost_strength * param_update)))
updates.append((param_update, momentum*param_update + (1. - momentum)*T.grad(cost, param)))
return updates
TensorFlow:
l2_loss = tf.add_n([tf.nn.l2_loss(v) for v in tf.trainable_variables()])
cost = cost + WEIGHT_COST_STRENGTH * l2_loss
train_op = tf.train.MomentumOptimizer(LEARNING_RATE, MOMENTUM).minimize(cost)
w(t)by adding the momentum term\alpha v(t-1), whilst tensorflow code actually subtracts it. According to this the tensorflow code seems to be more correct. – Vaenfila