What you could do is use lexer modes. For this you'd had to split grammar to parser and lexer grammar. Let's start with lexer grammar:
JSONLexer.g4
/** Taken from "The Definitive ANTLR 4 Reference" by Terence Parr */
// Derived from http://json.org
lexer grammar JSONLexer;
STRING
: '"' (ESC | ~ ["\\])* '"'
;
fragment ESC
: '\\' (["\\/bfnrt] | UNICODE)
;
fragment UNICODE
: 'u' HEX HEX HEX HEX
;
fragment HEX
: [0-9a-fA-F]
;
NUMBER
: '-'? INT '.' [0-9] + EXP? | '-'? INT EXP | '-'? INT
;
fragment INT
: '0' | [1-9] [0-9]*
;
// no leading zeros
fragment EXP
: [Ee] [+\-]? INT
;
// \- since - means "range" inside [...]
TRUE : 'true';
FALSE : 'false';
NULL : 'null';
LCURL : '{';
RCURL : '}';
COL : ':';
COMA : ',';
LBRACK : '[';
RBRACK : ']';
WS
: [ \t\n\r] + -> skip
;
NON_VALID_STRING : . ->pushMode(MODE_ERR);
mode MODE_ERR;
WS1
: [ \t\n\r] + -> skip
;
COL1 : ':' ->popMode;
MY_ERR_TOKEN : ~[':']* ->type(NON_VALID_STRING);
Basically I have added some tokens used in the parser part (like LCURL, COL, COMA etc) and introduced NON_VALID_STRING token, which is basically the first character that's nothing that already is (should be) matched. Once this token is detected, I switch the lexer to MODE_ERR mode. In this mode I go back to default mode once : is detected (this can be changed and maybe refined, but server the purpose here :) ) or I say that everything else is MY_ERR_TOKEN to which I assign NON_VALID_STRING token type. Here is what ATNLRWorks says to this when I run interpret lexer option with your input:
![ANTLRWorks lexer interpret]()
So s is NON_VALID_STRING type and so is everything else until :. So, same type but two different tokens. If you want them not to be of the same type, simply omit the type call in the lexer grammar.
Here is the parser grammar now
JSONParser.g4
/** Taken from "The Definitive ANTLR 4 Reference" by Terence Parr */
// Derived from http://json.org
parser grammar JSONParser;
options {
tokenVocab=JSONLexer;
}
json
: object
| array
;
object
: LCURL pair (COMA pair)* RCURL
| LCURL RCURL
;
pair
: STRING COL value
;
array
: LBRACK value (COMA value)* RBRACK
| LBRACK RBRACK
;
value
: STRING
| NUMBER
| object
| array
| TRUE
| FALSE
| NULL
;
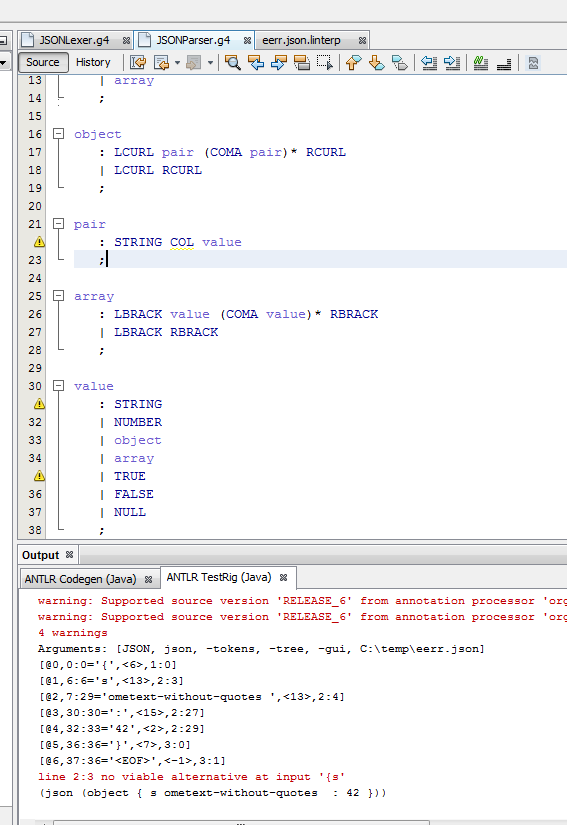
and if you run the test rig (I do it with ANTLRworks) you'll get a single error (see screenshot) ![antlworks parser]()
Also you could accumulate lexer errors by overriding the generated lexer class, but I understood in the question that this is not desired or I didn't understand that part :)