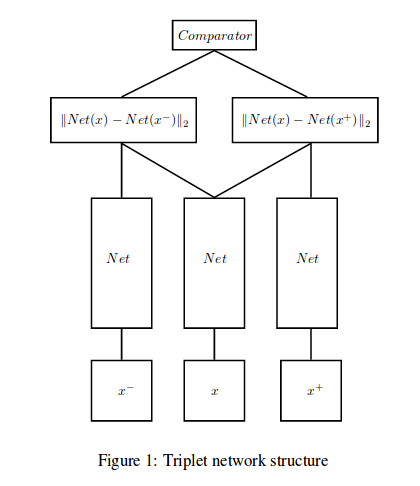
So I am performing a similar task of using Triplet loss for classification. Here is how I used the novel loss method with a classifier.
First, train your model using the standard triplet loss function for N epochs. Once you are sure that the model ( we shall refer to this as the embedding generator) is trained, save the weights as we shall be using these weights ahead.
Let's say that your embedding generator is defined as:
class EmbeddingNetwork(nn.Module):
def __init__(self):
super(EmbeddingNetwork, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 64, (7,7), stride=(2,2), padding=(3,3)),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.001),
nn.MaxPool2d((3, 3), 2, padding=(1,1))
)
self.conv2 = nn.Sequential(
nn.Conv2d(64,64,(1,1), stride=(1,1)),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.001),
nn.Conv2d(64,192, (3,3), stride=(1,1), padding=(1,1)),
nn.BatchNorm2d(192),
nn.LeakyReLU(0.001),
nn.MaxPool2d((3,3),2, padding=(1,1))
)
self.fullyConnected = nn.Sequential(
nn.Linear(7*7*256,32*128),
nn.BatchNorm1d(32*128),
nn.LeakyReLU(0.001),
nn.Linear(32*128,128)
)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.fullyConnected(x)
return torch.nn.functional.normalize(x, p=2, dim=-1)
Now we shall using this embedding generator to create another classifier, fit the weights we saved before to this part of the network and then freeze this part so our classifier trainer does not interfere with the triplet model. This can be done as:
class classifierNet(nn.Module):
def __init__(self, EmbeddingNet):
super(classifierNet, self).__init__()
self.embeddingLayer = EmbeddingNet
self.classifierLayer = nn.Linear(128,62)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.dropout(self.embeddingLayer(x))
x = self.classifierLayer(x)
return F.log_softmax(x, dim=1)
Now we shall load the weights we saved before and freeze them using:
embeddingNetwork = EmbeddingNetwork().to(device)
embeddingNetwork.load_state_dict(torch.load('embeddingNetwork.pt'))
classifierNetwork = classifierNet(embeddingNetwork)
Now train this classifier network using the standard classification losses like BinaryCrossEntropy or CrossEntropy.