The question in place is dependent on a lot of factors:
- hardware
- operating system (and its configuration)
- JVM implementation
- Network devices
- Server behaviour
First question - is the difference supposed to be this remarkable?
Depends on the load, pool size and network but it could be way more than the observed factor of 2 in each of the directions (in favour of Async or threaded solution). According to your later comment the difference is more because of a misconduct, but for the sake of argument I'll explain the possible cases.
Dedicated threads could be quite a burden. (Interrupt handling and thread scheduling is done by the operating system in case you are are using Oracle [HotSpot] JVM as these tasks are delegated.) The OS/system could become unresponsive if there are too many threads and thus slowing your batch processing (or other tasks). There are a lot of administrative tasks regarding thread management this is why thread (and connection) pooling is a thing. Although a good operating system should be able to handle a few thousand concurrent threads, there is always the chance that some limits or (kernel) event occur.
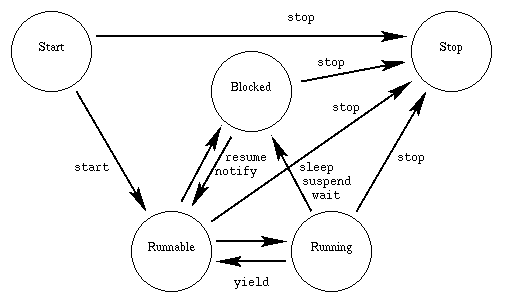
This is where pooling and async behaviour comes in handy. There is for example a pool of 10 phisical threads doing all the work. If something is blocked (waits for the server response in this case) it gets in the "Blocked" state (see image) and the following task gets the phisical thread to do some work. When a thread is notified (data arrived) it becomes "Runnable" (from which point the pooling mechanism is able to pick it up [this could be the OS or JVM implemented solution]). For further reading on the thread states I recommend W3Rescue. To understand the thread pooling better I recommend this baeldung article.
![Thread transitions]()
Second question - is something wrong with the async implementation? If not, what is the right approach to go about here?
The implementation is OK, there is no problem with it. The behaviour is just different from the threaded way. The main question in these cases are mostly what the SLA-s (service level agreements) are. If you are the only "customer of the service, then basically you have to decide between latency or throughput, but the decision will affect only you. Mostly this is not the case, so I would recommend some kind of pooling which is supported by the library you are using.
Third question - However I just noted that the time taken is roughly the same the moment you read the response stream as a string. I wonder why this is?
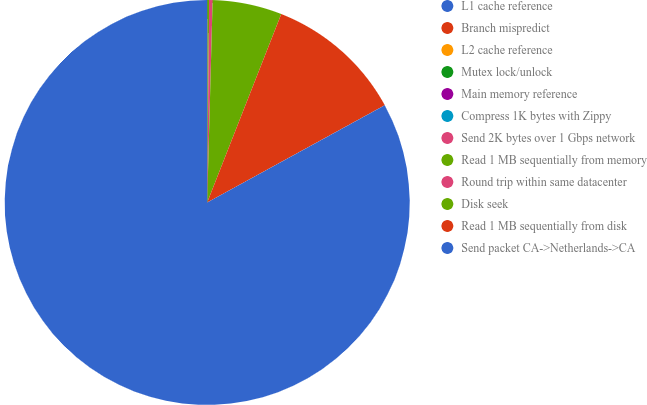
The message is most likely arrived completely in both cases (probably the response is not a stream just a few http package), but if you are reading the header only that does not need the response itself to be parsed and loaded on the CPU registers, thus reducing the latency of reading the actual data received. I think this is a cool represantation in latencies (source and source):
![Reach times]()
This came out as a quite long answer so TL.DR.: scaling is a really hardcore topic, it depends on a lot of things:
- hardware: number of phisical cores, multi-threading capacity, memory speed, network interface
- operating system (and its configuration): thread management, interruption handling
- JVM implementation: thread management (internal or outsourced to OS), not to mention GC and JIT configurations
- Network devices: some are limiting the concurrent connections from a given IP, some pools non
HTTPS connections and act as proxies
- Server behaviour: pooled workers or per-request workers etc
Most likely in your case the server was the bottleneck as both methods gave the same result in the corrected case (HttpResponse::getStatusLine().getStatusCode() and HttpURLConnection::getResponseCode()). To give a proper answer you should measure your servers performance with some tools like JMeter or LoadRunner etc and then size your solution accordingly. This article is more on DB connection pooling, but the logic is applicable in here as well.
HttpResponse::getStatusLine().getStatusCode()andHttpURLConnection::getResponseCode()respectively. However I just noted that the time taken is roughly the same the moment you read the response stream as a string. I wonder why this is? Both shouldn't be reading the response body unless the stream is read – Theater