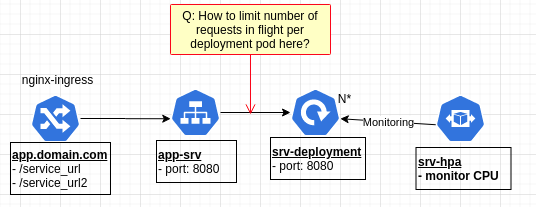
I am porting an application to run within k8s. I have run into an issue with ingress. I am trying to find a way to limit the number of REST API requests in flight at any given time to each backend pod managed by a deployment.
See the image below the shows the architecture.
Ingress is being managed by nginx-ingress. For a given set of URL paths, the ingress forwards the request to a service that targets a deployment of REST API backend processes. The deployment is also managed by an HPA based upon CPU load.
What I want to do is find a way to queue up ingress requests such that there are never more than X requests in flight to any pod running our API backend process. (ex. only allow 50 requests in flight at once per pod)
Does anyone know how to put a request limit in place like this?
As a bonus question, the next thing I would need to do is have the HPA monitor the request queuing and automatically scale up/down the deployment to match the number of pods to the number of requests currently being processed / queued. For example if each pod can handle 100 requests in flight at once and we currently have load levels of 1000 requests to handle, then autoscale to 10 pods.
If it is useful, I am also planning to have linkerd in place for this cluster. Perhaps it has a capability that could help.