I am implementing a project which needs to cluster geographical points. OPTICS algorithm seems to be a very nice solution. It needs just 2 parameters as input(MinPts and Epsilon), which are, respectively, the minimum number of points needed to consider them as a cluster, and the distance value used to compare if two points are in can be placed in same cluster.
My problem is that, due to the extreme variety of the points, I can't set a fixed epsilon. Just look at the image below.
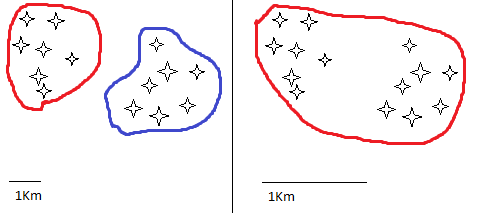
The same points structure but in a different scale would result very different. Suppose to set MinPts=2 and epsilon = 1Km. On the left, the algorithm would create 2 clusters(red and blue), but on the right it would create one single cluster containing all of the points(red), but I would like to obtain 2 clusters even on the right.
So my question is: is there any kind of way to calculate dynamically the epsilon value to get this result?
EDIT 05 June 2012 3.15pm: I thought I was using the OPTICS algorithm implementation from the javaml library, but it seems it is actually a DBSCAN algorithm implementation. So the question now is: does anybody know a java based implementation of OPTICS algorithm?
Thank you very much and excuse my for my poor english.
Marco