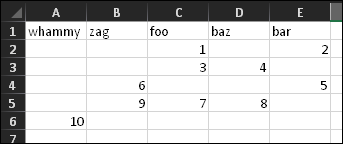
I am parsing a large piece of text into dictionaries, with the end objective of creating a CSV file with the keys as column headers.
csv.DictWriter(csvfile, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, **kwds)
The problem arises as the dict for any 'n'th row can include a new, never before used key. I then want the CSV to contain a column for this new key as well. In short, all my fields are not known beforehand so I cannot compile a complete fieldnames at the beginning.
Is there a recommended way to have csv.DictWriter not ignore missing fields but add them to fieldnames instead? Merely changing fieldnames at this point would leave the prior lines with an incorrectly lower number of fields.

{kind=link}