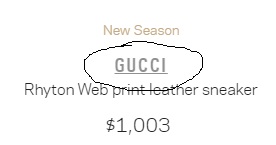
I've written a script in php to scrape the title of a product located at the top right corner in a webpage. The title is visible as Gucci.
when I execute my below script, it gives me an error Notice: Trying to get property 'plaintext' of non-object in C:\xampp\htdocs\runcode\testfile.php on line 16.
How can I get only the name Gucci from that webpage?
I've written so far:
<?php
include "simple_html_dom.php";
$link = "https://www.farfetch.com//bd/shopping/men/gucci-rhyton-web-print-leather-sneaker-item-12964878.aspx";
function get_content($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, array('User-Agent: Mozilla/5.0',));
curl_setopt($ch, CURLOPT_BINARYTRANSFER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$htmlContent = curl_exec($ch);
curl_close($ch);
$dom = new simple_html_dom();
$dom->load($htmlContent);
$itemTitle = $dom->find('#bannerComponents-Container [itemprop="name"]', 0)->plaintext;
echo "{$itemTitle}";
}
get_content($link);
?>
Btw, the selector I've used within the script is flawless.
To clear the confusion I've copied a chunk of html elements from the page source which neither generats dynamically nor javascript encrypted so I don't find any reason for curl not to be able to handle that:
<div class="cdb2b6" id="bannerComponents-Container">
<p class="_41db0e _527bd9 eda00d" data-tstid="merchandiseTag">New Season</p>
<div class="_1c3e57">
<h1 class="_61cb2e" itemProp="brand" itemscope="" itemType="http://schema.org/Brand">
<a href="/bd/shopping/men/gucci/items.aspx" class="fd9e8e e484bf _4a941d f140b0" data-trk="pp_infobrd" data-tstid="cardInfo-title" itemProp="url" aria-label="Gucci">
<span itemProp="name">Gucci</span>
</a>
</h1>
</div>
</div>
Post script: It's very pathetic that I had to show a real life example from another language to make sure the name Gucci is not dynamically generated as few comments and an answer have already indicated that
The following script is written in python (using requests module which can't handle dynamic content):
import requests
from bs4 import BeautifulSoup
url = "https://www.farfetch.com//bd/shopping/men/gucci-rhyton-web-print-leather-sneaker-item-12964878.aspx"
with requests.Session() as s:
s.headers["User-Agent"] = "Mozilla/5.0"
res = s.get(url)
soup = BeautifulSoup(res.text,"lxml")
item = soup.select_one('#bannerComponents-Container [itemprop="name"]').text
print(item)
Output It produces:
Gucci
Now, it's clear that the content I look for is static.
Please check out the below image to recognize the title which I've already marked by a pencil.
$itemTitle = $dom->find('#bannerComponents-Container [itemprop="name"]', 0);return an object? – Fourinhand[itemProp=name](capital P for some reason) – Preter