I was optimising a query on SQL Server and ran into something I was not expecting. There is a table tblEvent in the database, among other columns it has IntegrationEventStateId and ModifiedDateUtc. There is an index by these columns:
create index IX_tblEvent_IntegrationEventStateId_ModifiedDateUtc
on dbo.tblEvent (
IntegrationEventStateId,
ModifiedDateUtc
)
When I execute the following statement:
select *
from dbo.tblEvent e
where
e.IntegrationEventStateId = 1
or e.IntegrationEventStateId = 2
or e.IntegrationEventStateId = 5
or (e.IntegrationEventStateId = 4 and e.ModifiedDateUtc >= dateadd(minute, -5, getutcdate()))
I get this execution plan (note the index does NOT get used):
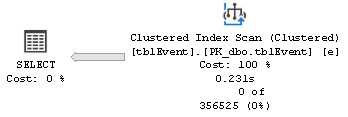
But when I execute this statement:
select *
from dbo.tblEvent e
where
1 = e.IntegrationEventStateId
or 2 = e.IntegrationEventStateId
or 5 = e.IntegrationEventStateId
or (4 = e.IntegrationEventStateId and e.ModifiedDateUtc >= dateadd(minute, -5, getutcdate()))
I get this execution plan (note the index DOES get used):
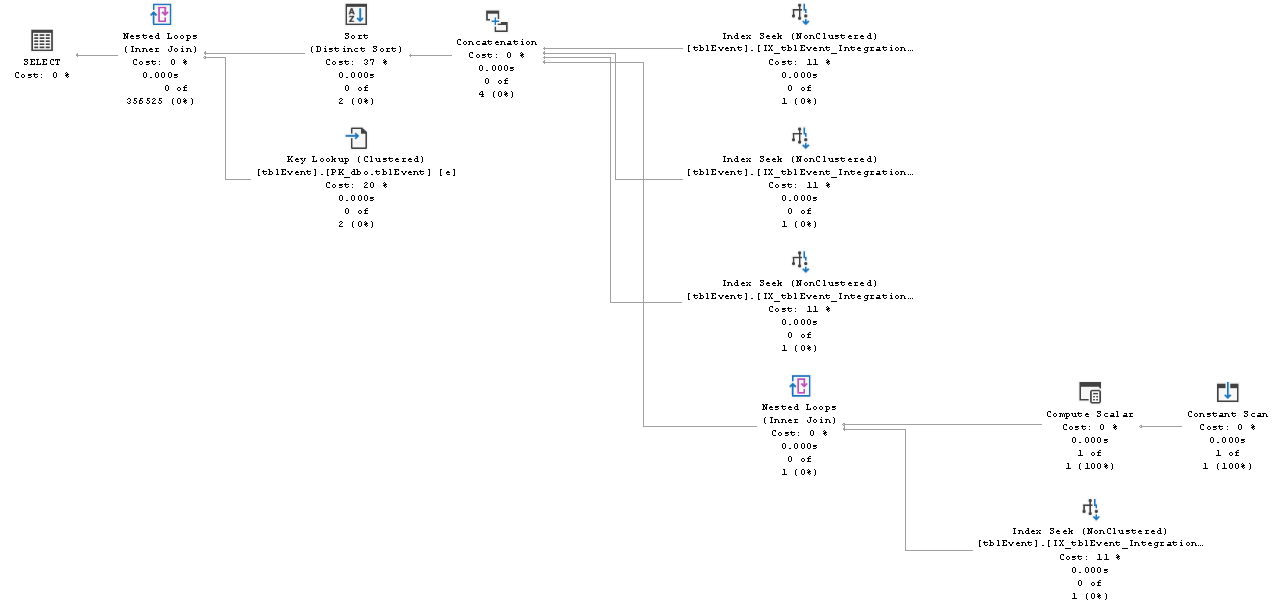
The only difference between the two statements is the order of comparisons in the where clause. Can anyone please explain why I get different execution plans?
Update 1 - a full repro script is below
CREATE TABLE dbo.tblEvent
(
EventId INT IDENTITY PRIMARY KEY,
IntegrationEventStateId INT,
ModifiedDateUtc DATETIME,
OtherCol CHAR(1),
index IX_tblEvent_IntegrationEventStateId_ModifiedDateUtc(IntegrationEventStateId, ModifiedDateUtc)
);
INSERT INTO dbo.tblEvent
SELECT TOP 356525 3,
DATEADD(SECOND, ROW_NUMBER() OVER (ORDER BY @@SPID)%63424, GETUTCDATE()),
'A'
FROM sys.all_objects o1,
sys.all_objects o2;
UPDATE STATISTICS dbo.tblEvent WITH FULLSCAN
select *
from dbo.tblEvent e
where
e.IntegrationEventStateId = 1
or e.IntegrationEventStateId = 2
or e.IntegrationEventStateId = 5
or (e.IntegrationEventStateId = 4 and e.ModifiedDateUtc >= dateadd(minute, -5, getutcdate()))
select *
from dbo.tblEvent e
where
1 = e.IntegrationEventStateId
or 2 = e.IntegrationEventStateId
or 5 = e.IntegrationEventStateId
or (4 = e.IntegrationEventStateId and e.ModifiedDateUtc >= dateadd(minute, -5, getutcdate()))
Update 2 - DDL of the original table
CREATE TABLE [dbo].[tblEvent]
(
[EventId] [int] NOT NULL IDENTITY(1, 1),
[EventTypeId] [int] NOT NULL,
[ScorecardId] [int] NULL,
[ScorecardAreaId] [int] NULL,
[AreaId] [int] NULL,
[ScorecardTopicId] [int] NULL,
[TopicId] [int] NULL,
[ScorecardRequirementId] [int] NULL,
[RequirementId] [int] NULL,
[DocumentId] [int] NULL,
[FileId] [int] NULL,
[TopicTitle] [nvarchar] (100) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ScorecardTopicStatus] [nvarchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[RequirementText] [nvarchar] (500) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ScorecardRequirementStatus] [nvarchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[DocumentName] [nvarchar] (260) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CreatedByUserId] [int] NOT NULL,
[CreatedByUserSessionId] [int] NOT NULL,
[CreatedDateUtc] [datetime2] (4) NOT NULL CONSTRAINT [DF__tblEvent__Create__0737E4A2] DEFAULT (sysutcdatetime()),
[CreatedDateLocal] [datetime2] (4) NOT NULL CONSTRAINT [DF__tblEvent__Create__082C08DB] DEFAULT (sysdatetime()),
[ModifiedByUserId] [int] NOT NULL,
[ModifiedByUserSessionId] [int] NOT NULL,
[ModifiedDateUtc] [datetime2] (4) NOT NULL CONSTRAINT [DF__tblEvent__Modifi__09202D14] DEFAULT (sysutcdatetime()),
[ModifiedDateLocal] [datetime2] (4) NOT NULL CONSTRAINT [DF__tblEvent__Modifi__0A14514D] DEFAULT (sysdatetime()),
[IsDeleted] [bit] NOT NULL,
[RowVersion] [timestamp] NOT NULL,
[ScorecardRequirementPriority] [nvarchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[AffectedUserId] [int] NULL,
[UserId] [int] NULL,
[CorrelationId] [nvarchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[IntegrationEventStateId] [int] NULL,
[IntegrationEventId] [nvarchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[IntegrationEventContent] [nvarchar] (max) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[IntegrationEventType] [nvarchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[IntegrationEventTryCount] [int] NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[tblEvent] ADD CONSTRAINT [PK_dbo.tblEvent] PRIMARY KEY CLUSTERED ([EventId]) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_tblEvent_IntegrationEventStateId_ModifiedDateUtc] ON [dbo].[tblEvent] ([IntegrationEventStateId], [ModifiedDateUtc]) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tblEvent] ADD CONSTRAINT [FK_dbo.tblEvent_dbo.tblEventType_EventTypeId] FOREIGN KEY ([EventTypeId]) REFERENCES [dbo].[tblEventType] ([EventTypeId])
GO
ALTER TABLE [dbo].[tblEvent] ADD CONSTRAINT [FK_dbo.tblEvent_dbo.tblIntegrationEventState_IntegrationEventStateId] FOREIGN KEY ([IntegrationEventStateId]) REFERENCES [dbo].[tblIntegrationEventState] ([IntegrationEventStateId])
GO

Microsoft SQL Server 2016 (SP1-CU5) (KB4040714) - 13.0.4451.0 (X64) Sep 5 2017 16:12:34 Copyright (c) Microsoft Corporation Standard Edition (64-bit) on Windows Server 2012 R2 Standard 6.3 <X64> (Build 9600: ) (Hypervisor). DB compatibility level:SQL Server 2016 (130). The behaviour is repeatable, I ran the queries multiple times and consistently got the above execution plans. – Coccidioidomycosiswhere 1=1to the first plan? – WasherStatementOptmEarlyAbortReason="GoodEnoughPlanFound", the first does not. Still looking. – YoonDBCC FREEPROCCACHEbeforehand? (I'm assuming this isn't a production server, by the way.) – Yoonand 1=1, and queries with addedor 1=0, executingDBCC FREEPROCCACHEevery time before I execute the query. No change in exec plans. – Coccidioidomycosis356,525rows are going to meet the predicate - i.e. 100% of the rows in the table. This is probably why it doesn't do a plan with seek + lookups. Unclear why it would estimate that when the estimates for the individual seeks add up to4in the second plan – LoggerIX_tblEvent_IntegrationEventStateId_ModifiedDateUtclook like? I can reproduce the bad estimates if I insert 356,525 rows - all of which have3forIntegrationEventStateId- but this applies to both queries – Logger[ModifiedDateUtc] [datetime2] (4) NOT NULL CONSTRAINT [DF__tblEvent__Modifi__09202D14] DEFAULT (sysutcdatetime())– Coccidioidomycosisdbcc freeproccache, to confirm that I still get the same exec plans with the statistics I'm posting. – Coccidioidomycosisdatetime2(4), it made no difference. – Coccidioidomycosis