I've been saving some tick data in TimescaleDB and have been surprised at how much space it's been taking up. I'm pretty new to this but I'm saving roughly 10 million rows a day into a table that has the following columns:
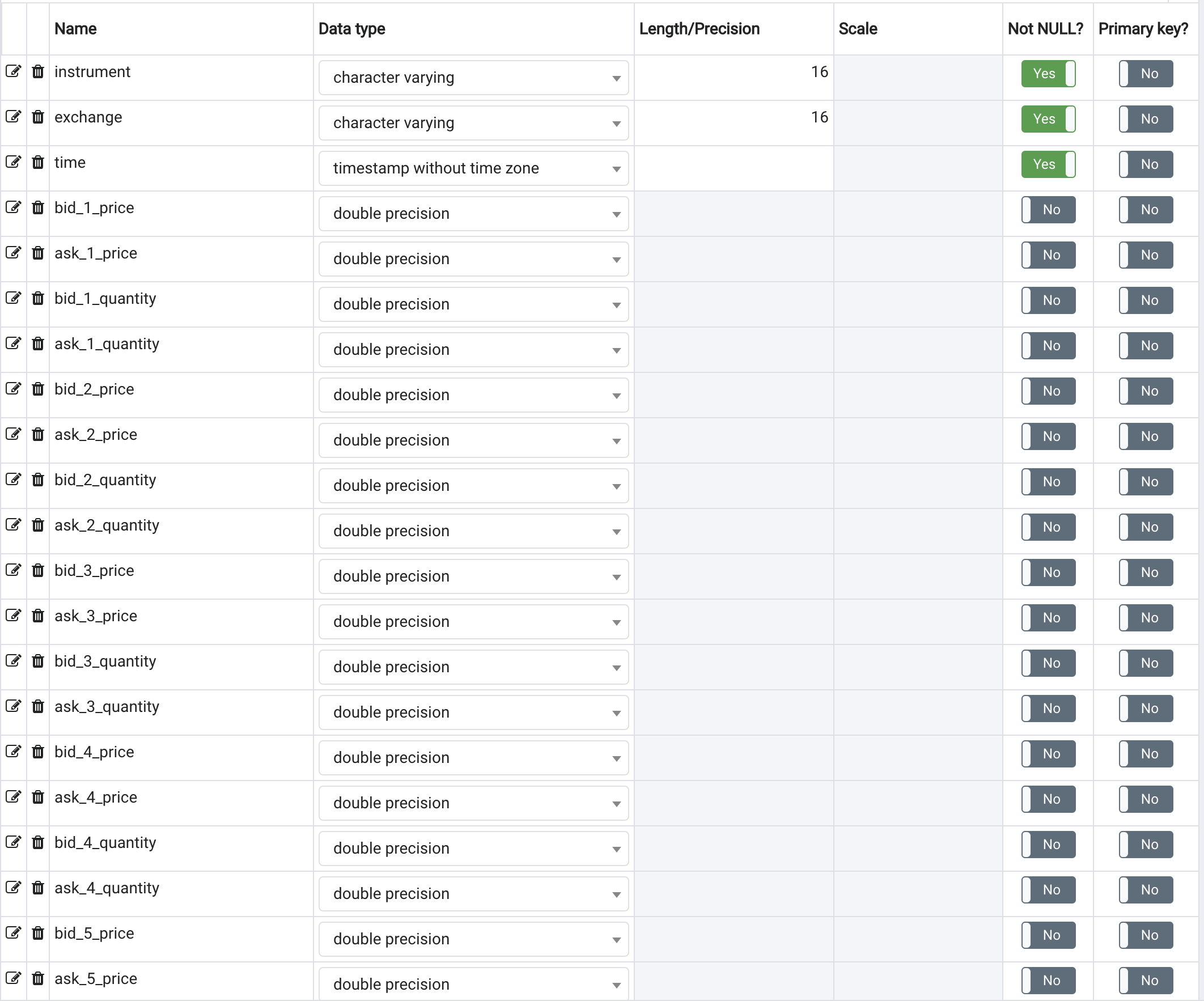
This has been taking up roughly 35GB a day, which seems excessive. I was wondering what steps I can take to reduce this amount - if I changed the doubles column to float, would this have a big impact? Are there any other ways to reduce this size?
EDIT:
The results of running chunk_relation_size_pretty() are:

and hypertable_relation_size_pretty():

It also seems very strange that the index is taking up so much space - I tried querying the data over a certain range of data and the results took quite a while to get back (roughly 10 minutes for a day's worth of data). The index is currently set as a composite index between (instrument, exchange, time DESC).
pgstattuplesay about the table? – Ladinghypertable_relation_size_pretty()andchunk_relation_size_pretty()– BogleVACUUM ANALYZE? Do you know if it was run? – Bogle