Compacted kafka topics themselves and basic Consumer/Producer kafka APIs are not suitable for a key-value database. They are, however, widely used as a backstore to persist KV Database/Cache data, i.e: in a write-through approach for instance. If you need to re-warmup your Cache for some reason, just replay the entire topic to repopulate.
In the Kafka world you have the Kafka Streams API which allows you to expose the state of your application, i.e: for your KV use case it could be the latest state of an order, by the means of queryable state stores. A state store is an abstraction of a KV Database and are actually implemented using a fast KV database called RocksDB which, in case of disaster, are fully recoverable because it's full data is persisted in a kafka topic, so it's quite resilient as to be a source of the data for your use case.
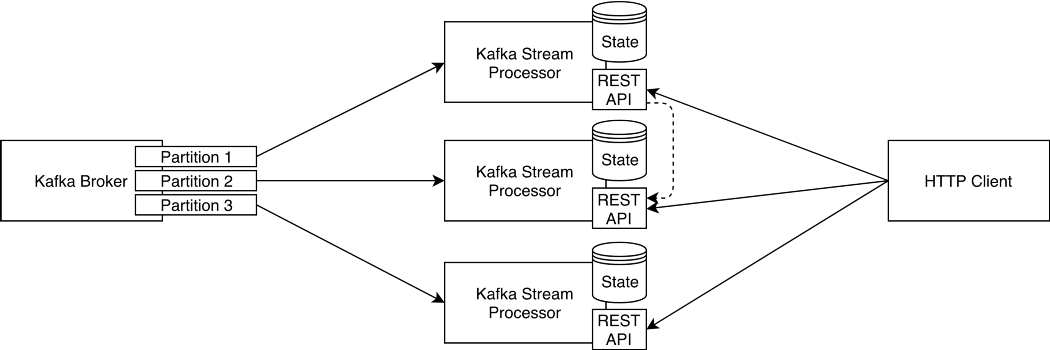
Imagine that this is your Kafka Streams Application architecture:
![enter image description here]()
To be able to query these Kafka Streams state stores you need to bundle an HTTP Server and REST API in your Kafka Streams applications to query its local or remote state store (Kafka distributes/shards data across multiple partitions in a topic to enable parallel processing and high availability, and so does Kafka Streams). Because Kafka Streams API provides the metadata for you to know in which instance the key resides, you can surely query any instance and, if the key exists, a response can be returned regardless of the instance where the key lives.
![enter image description here]()
With this approach, you can kill two birds in a shot:
- Do stateful stream processing at scale with Kafka Streams
- Expose its state to external clients in a KV Database query pattern style
All in a real-time, highly performant, distributed and resilient architecture.
The images were sourced from a wider article by Robert Schmid where you can find additional details and a prototype to implement queryable state stores with Kafka Streams.
Notable mention:
If you are not in the mood to implement all of this using the Kafka Streams API, take a look at ksqlDB from Confluent which provides an even higher level abstraction on top of Kafka Streams just using a cool and simple SQL dialect to achieve the same sort of use case using pull queries. If you want to prototype something really quickly, take a look at this answer by Robin Moffatt or even this blog post to get a grip on its simplicity.
While ksqlDB is not part of the Apache Kafka project, it's open-source, free and is built on top of the Kafka Streams API.