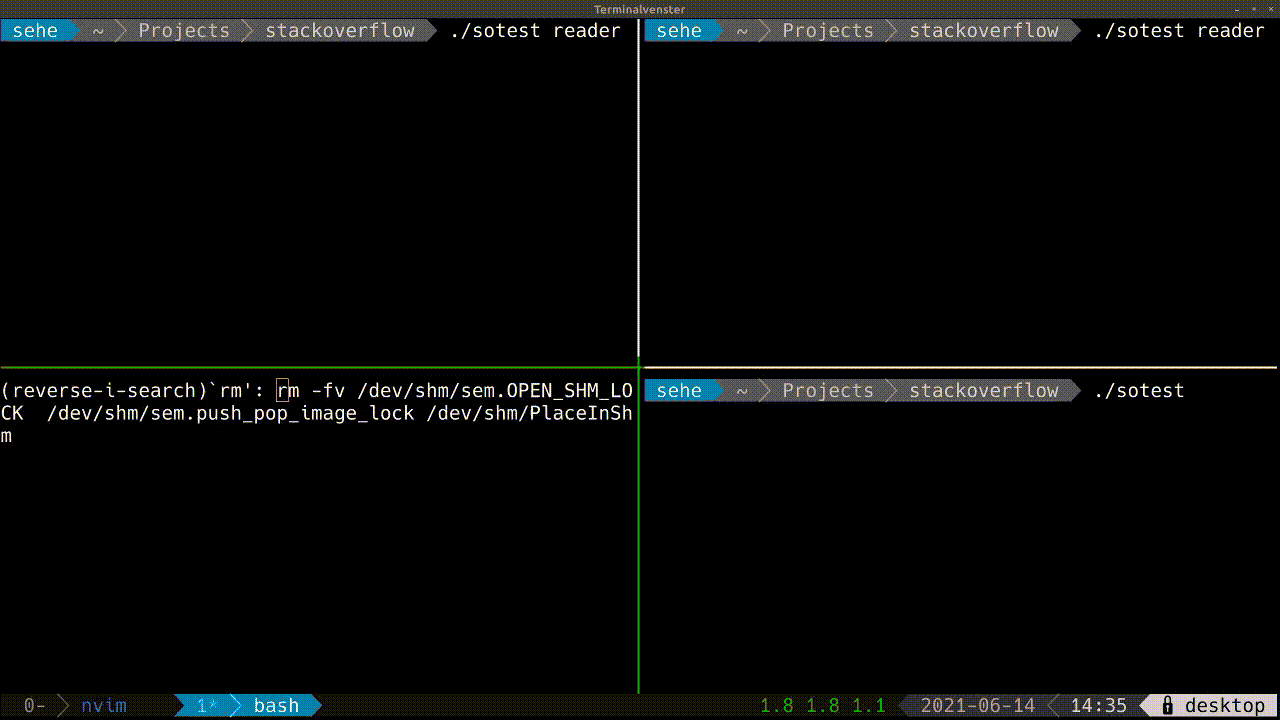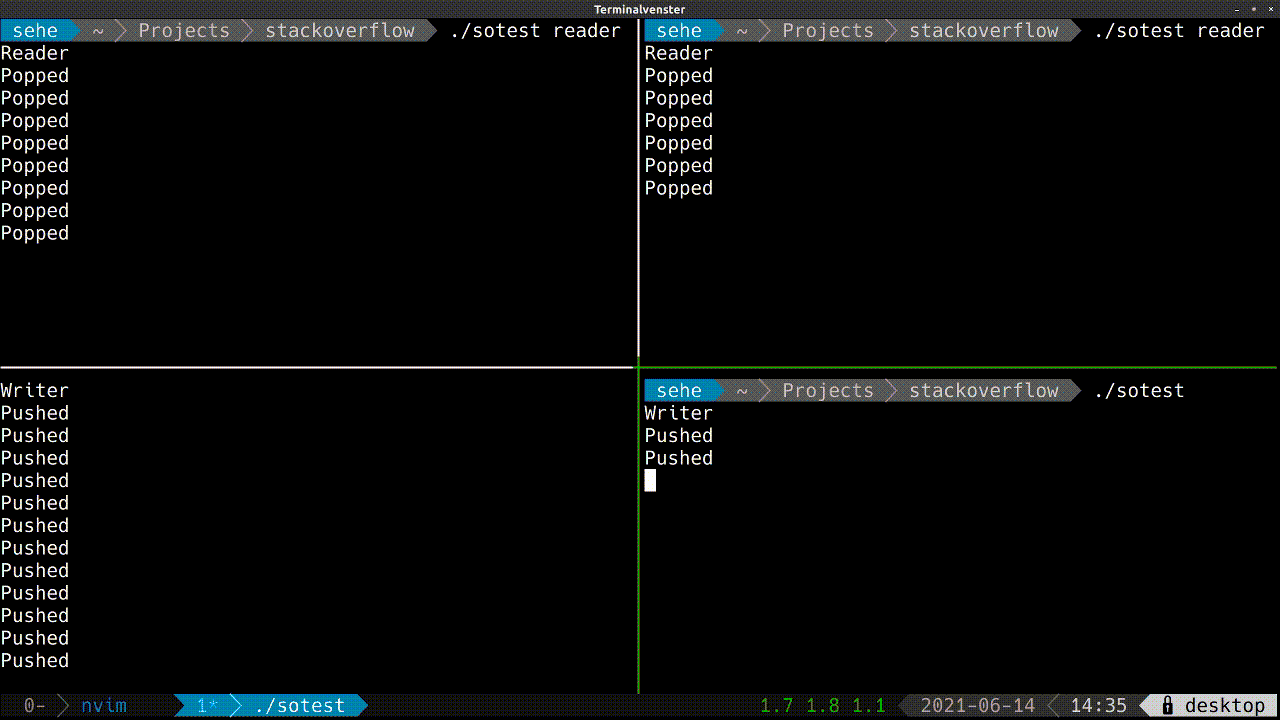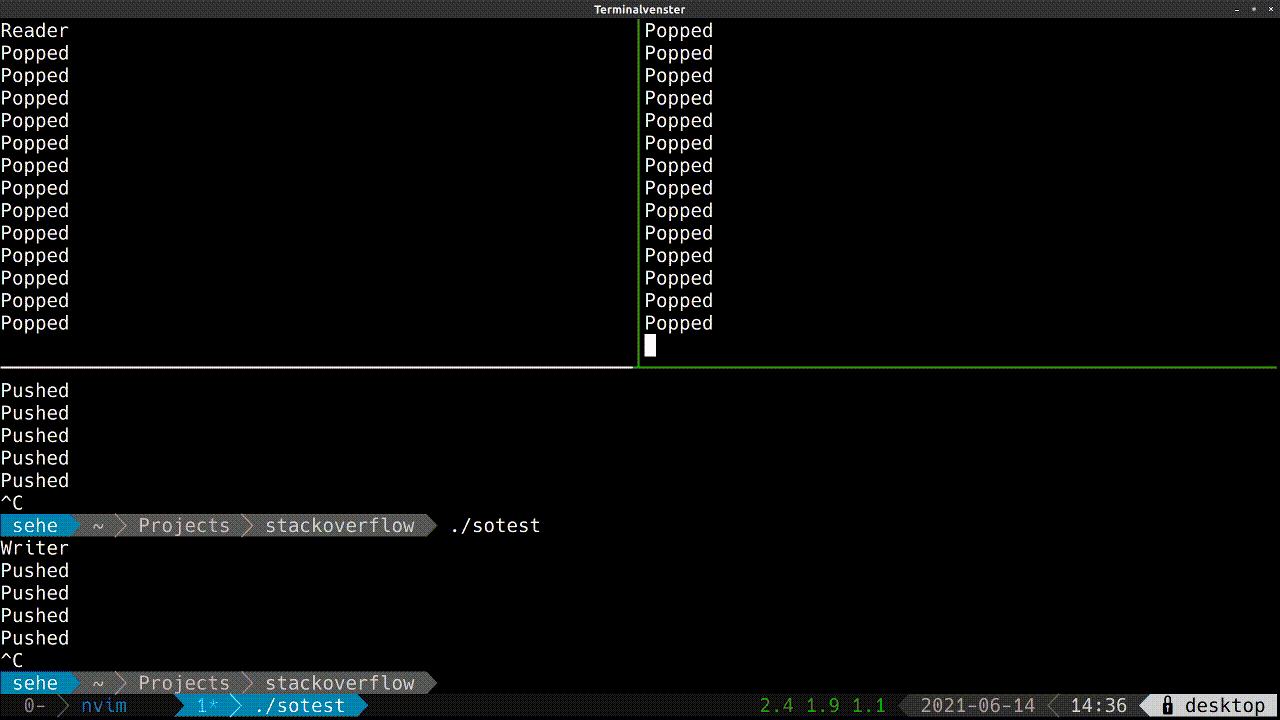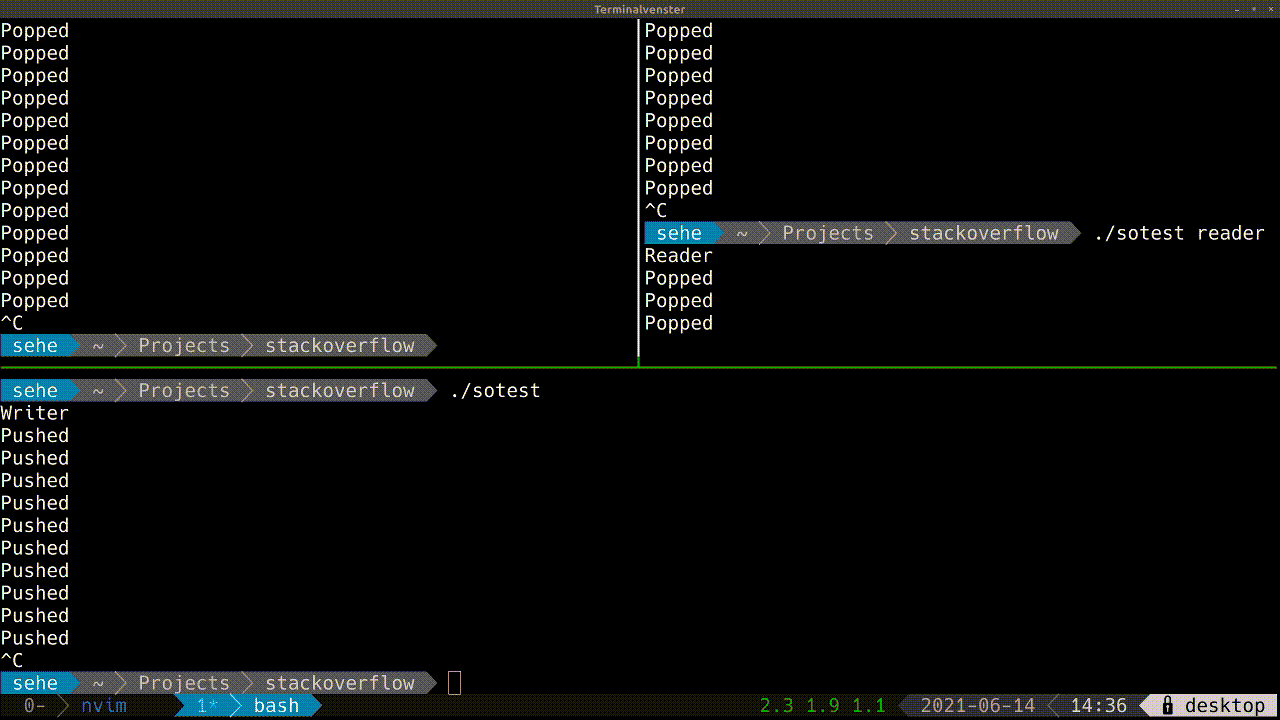
I am using boost's ipc library for saving complex object, include images, in shared memory, used by several processes. Let's call this object MyImage. The shared memory is a circular buffer saving several MyImage objects at a time.
In my code there are two (or more) processes writing to a segment in a shared memory, and another one reading from it. This flow works as expected, but after the reader process is done, or crashed, when it tries to open the same object in shared memory again it get stuck on find method, while the writer processes are still running fine.
I tried to understand which race condition could cause this, but couldn't find any explanation in my code, or in boost's documentation.
Here is a simple code exampled the problem in my project:
The Writer process:
#include <boost/interprocess/managed_shared_memory.hpp>
#include <boost/interprocess/ipc/message_queue.hpp>
#include <boost/interprocess/allocators/allocator.hpp>
#include <boost/circular_buffer.hpp>
using namespace std;
namespace bip = boost::interprocess;
static const char *const PLACE_SHM_NAME = "PlaceInShm";
static const char *const OBJECT_SHM_NAME = "ObjectInShm";
static const char *const PUSH_POP_LOCK = "push_pop_image_lock";
static const int IMAGES_IN_BUFFER = 20;
static const int OBJECT_SIZE_IN_SHM = 91243520;
class MyImage;
typedef bip::managed_shared_memory::segment_manager SegmentManagerType;
typedef bip::allocator<void, SegmentManagerType> MyImageVoidAllocator;
typedef bip::deleter<MyImage, SegmentManagerType> MyImageDeleter;
typedef bip::shared_ptr<MyImage, MyImageVoidAllocator, MyImageDeleter> MyImageSharedPtr;
typedef bip::allocator<MyImageSharedPtr, bip::managed_shared_memory::segment_manager> MyImageShmemAllocator;
typedef boost::circular_buffer<MyImageSharedPtr, MyImageShmemAllocator> MyImageContainer;
MyImageSharedPtr GetMyImage() {
// some implementation
return nullptr;
}
int main(int argc, char *argv[]) {
MyImageContainer *my_image_data_container;
try {
bip::named_mutex open_lock{bip::open_or_create, OPEN_SHM_LOCK};
bip::managed_shared_memory image_segment = bip::managed_shared_memory(bip::open_or_create, PLACE_SHM_NAME, OBJECT_SIZE_IN_SHM);
my_image_data_container = image_segment.find_or_construct<MyImageContainer>(OBJECT_SHM_NAME)(IMAGES_IN_BUFFER, image_segment.get_segment_manager());
} catch (boost::interprocess::interprocess_exception &e) {
exit(1);
}
boost::interprocess::named_mutex my_image_mutex_ptr(boost::interprocess::open_or_create, PUSH_POP_LOCK);
while (true) {
MyImageSharedPtr img = GetMyImage();
my_image_mutex_ptr.lock();
my_image_data_container->push_back(img);
my_image_mutex_ptr.unlock();
usleep(1000);
}
}
The Reader process:
int main(int argc, char *argv[]) {
MyImageContainer *my_image_data_container;
try {
bip::named_mutex open_lock{bip::open_only, OPEN_SHM_LOCK};
bip::scoped_lock<bip::named_mutex> lock(open_lock, bip::try_to_lock);
bip::managed_shared_memory image_segment = bip::managed_shared_memory(bip::open_only, PLACE_SHM_NAME);
my_image_data_container = image_segment.find<MyImageContainer>(OBJECT_SHM_NAME).first;
} catch (boost::interprocess::interprocess_exception &e) {
exit(1);
}
boost::interprocess::named_mutex my_image_mutex_ptr(boost::interprocess::open_or_create, PUSH_POP_LOCK);
while (true) {
if (my_image_data_container->size() == 0) {
continue;
}
MyImage *img;
my_image_mutex_ptr.lock();
img = &(*my_image_data_container->at(0));
my_image_data_container->pop_front();
my_image_mutex_ptr.unlock();
// do stuff with img
usleep(1000);
}
}
The flow to reproduce the bug:
- Run two processes of the
Writercode. - Run one process of the
Readercode. - kill the
Readerprocess. - run the
Readerprocess again.
At the second run, the process is stuck in the line image_segment.find<MyImageContainer>(OBJECT_SHM_NAME).first; while the Writer processes are fine.
Important to mention that each Writer process have a unique id, and write to the buffer in the shared memory only int(IMAGES_IN_BUFFER / NUMBER_OF_WRITERS) images starting from the index as his id.
For example, I have two Writers with id 0 and id 1, IMAGES_IN_BUFFER=20, then Writer 0 will write to indexes 0-9 and Writer 1 to 10-19.
Some of my debugging process:
- I tried to open the shared memory in a separate thread, using the
futureobject, and set a timeout of few seconds. But the whole process is still stuck. - When I kill the process after it is stuck, and re-run it, it never succeed again, unless I delete the object from shared memory and re-run all of the processes, include the
Writers. - Usually when running with one
WriterI couldn't reproduce the bug, but I can't say for sure. - It is not consistent, meaning I can't tell when it will get stuck and when not.
- Maybe the object in the shared memory is corrupted somehow, while the
Readerprocesses is crashing, and then to while reopen it, it fails. In that case I expect that boost will raise an exception not hang. - When the process exit gracefully, with exit code 0, it can happen as well.
Waiting to hear some opinions about what can be the cause of the process getting stuck. Thanks in advance!