I'm fine tuning a pre-trained bert model and i have a weird problem: When i'm fine tuning using the CPU, the code saves the model like this:
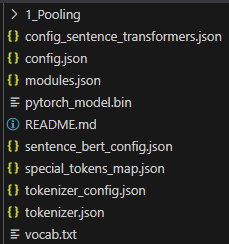
With the "pytorch_model.bin". But when i use CUDA (that i have to), the model is saved like this:
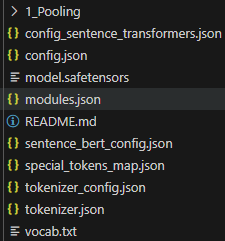
When i try to load this "model.safetensors" in the future, it raises an error "pytorch_model.bin" not found. I'm using two differents venvs to test using the CPU and CUDA.
How to solve this? is some version problem?
I'm using sentence_transformers framework to fine-tune the model.
Here's my training code:
checkpoint = 'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2'
word_embedding_model = models.Transformer(checkpoint, cache_dir=f'model/{checkpoint}')
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), pooling_mode='mean')
model = SentenceTransformer(modules=[word_embedding_model, pooling_model], device='cuda')
train_loss = losses.CosineSimilarityLoss(model)
evaluator = evaluation.EmbeddingSimilarityEvaluator.from_input_examples(val_examples, name='sbert')
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=5, evaluator=evaluator, show_progress_bar=True, output_path=f'model_FT/{checkpoint}', save_best_model=True)
I did try the tests in two differentes venvs, and i'm expecting the code to save a "pytorch_model.bin" not a "model.safetensors".
EDIT: i really don't know yet, but it seems that is the newer versions of transformers library that causes this problem. I saw that with hugging-face is possible to load the safetensors, but with Sentence-transformers (that i need to use) it's not.