I am looking for some assistance with writing API results to a .CSV file using Python. At this point, I'm successfully writing to .CSV, but I cannot seem to nail down the code behind the .CSV format I'm looking for, which is the standard one field = one column format.
Any help is appreciated! Details are below. Thanks!
My code:
import requests
import json
import csv
urlcomp = 'http://url_ommitted/api/reports/completion?status=COMPLETED&from=2016-06-01&to=2016-08-06'
headers = {'authorization': "Basic API Key Ommitted", 'accept': "application/json", 'accept': "text/csv"}
## API Call to retrieve report
rcomp = requests.get(urlcomp, headers=headers)
## API Results
data = rcomp.text
## Write API Results to CSV
with open('C:\_Python\\testCompletionReport.csv', "wb") as csvFile:
writer = csv.writer(csvFile, delimiter=',')
for line in data:
writer.writerow(line)
The code above creates a .CSV with the correct output, but it's writing each character from the API results into a new cell in Column A of the output file. Screenshot below:
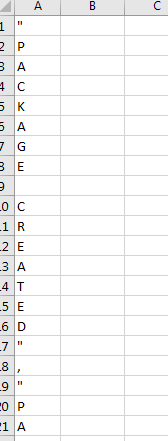
I've also attempted the code below, which writes the entire API result set into a single cell in the .CSV output file.
Code:
data = rcomp.text
with open('C:\_Python\\CompletionReportOutput.csv', 'wb') as csvFile:
writer = csv.writer(csvFile, delimiter = ',')
writer.writerow([data])
Output:

Below is a screenshot of some sample API result data returned from my call:
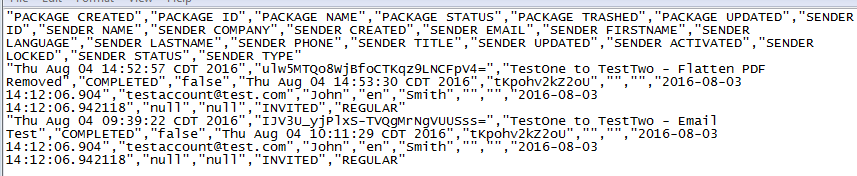
Example of what I'm looking for in the final .CSV output file:

EDIT - Sample API Response:
"PACKAGE CREATED","PACKAGE ID","PACKAGE NAME","PACKAGE STATUS","PACKAGE TRASHED","PACKAGE UPDATED","SENDER ID","SENDER NAME","SENDER COMPANY","SENDER CREATED","SENDER EMAIL","SENDER FIRSTNAME","SENDER LANGUAGE","SENDER LASTNAME","SENDER PHONE","SENDER TITLE","SENDER UPDATED","SENDER ACTIVATED","SENDER LOCKED","SENDER STATUS","SENDER TYPE" "Thu Aug 04 14:52:57 CDT 2016","ulw5MTQo8WjBfoCTKqz9LNCFpV4=","TestOne to TestTwo - Flatten PDF Removed","COMPLETED","false","Thu Aug 04 14:53:30 CDT 2016","tKpohv2kZ2oU","","","2016-08-03 14:12:06.904","[email protected]","John","en","Smith","","","2016-08-03 14:12:06.942118","null","null","INVITED","REGULAR" "Thu Aug 04 09:39:22 CDT 2016","IJV3U_yjPlxS-TVQgMrNgVUUSss=","TestOne to TestTwo - Email Test","COMPLETED","false","Thu Aug 04 10:11:29 CDT 2016","tKpohv2kZ2oU","","","2016-08-03 14:12:06.904","[email protected]","John","en","Smith","","","2016-08-03 14:12:06.942118","null","null","INVITED","REGULAR"
SECOND EDIT - Output from Lee's suggestion:

;- possibly different for other languages. – Lumenhourjsonin response which you're converting? At a glance, I don't see how you could reasonably separate out the newlines in the screenshot response and be sure that you have the correct data going into the correct columns, they're different lengths - surely the raw structure is more sensible? – Marjoriemarjorytxtbut I can't replicate what I think is just\nsplit being added indata = rcomp.text. I thinkdata = recomp.json()will make this much easier to split out :) – Marjoriemarjory