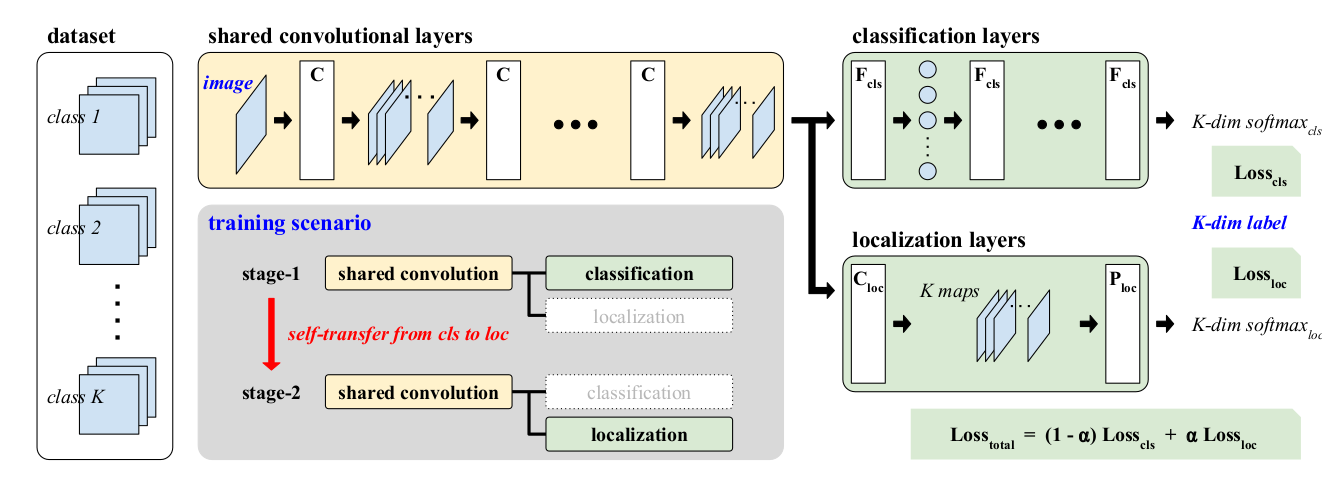
For this question, a more elaborated solution is necessary. Since we're going to use a trainable weight, we will need a custom layer.
Also, we will be needing a different form of training, since our loss doesn't work like the others taking only y_true and y_pred and considers joining two different outputs.
Thus, we're going to create two versions of the same model, one for prediction, another for training, and the training version will contain the loss in itself, using a dummy keras loss function in compilation.
The prediction model
Let's use a very basic example of model with two outputs and one input:
#any input your true model takes
inp = Input((5,5,2))
#represents the localization output
outImg = Conv2D(1,3,activation='sigmoid')(inp)
#represents the classification output
outClass = Flatten()(inp)
outClass = Dense(2,activation='sigmoid')(outClass)
#the model
predictionModel = Model(inp, [outImg,outClass])
You use this one regularly for predictions. It's not necessary to compile this one.
The losses for each branch
Now, let's create custom loss functions for each branch, one for LossCls and another for LossLoc.
Using dummy examples here, you can elaborate these losses better if necessary. The most important is that they output batches shaped like (batch, 1) or (batch,). Both output the same shape so they can be summed later.
def calcImgLoss(x):
true,pred = x
loss = binary_crossentropy(true,pred)
return K.mean(loss, axis=[1,2])
def calcClassLoss(x):
true,pred = x
return binary_crossentropy(true,pred)
These will be used in Lambda layers in the training model.
The loss weighting layer - (WARNING! EDITED! - See explanation at the end)
Now, let's weight the losses with the trainable alpha. Trainable parameters need custom layers to be implemented.
class LossWeighter(Layer):
def __init__(self, **kwargs): #kwargs can have 'name' and other things
super(LossWeighter, self).__init__(**kwargs)
#create the trainable weight here, notice the constraint between 0 and 1
def build(self, inputShape):
self.weight = self.add_weight(name='loss_weight',
shape=(1,),
initializer=Constant(0.5),
constraint=Between(0,1),
trainable=True)
super(LossWeighter,self).build(inputShape)
def call(self,inputs):
#old answer: will always tend to completely ignore the biggest loss
#return (self.weight * firstLoss) + ((1-self.weight)*secondLoss)
#problem: alpha tends to 0 or 1, eliminating the biggest of the two losses
#proposal of working alpha optimization
#return K.square((self.weight * firstLoss) - ((1-self.weight)*secondLoss))
#problem: might not train any of the losses, and even increase one of them
#in order to minimize the difference between the two losses
#new answer - a mix between the two, applying gradients to the right weights
loss1, loss2 = inputs #trainable
static_loss1 = K.stop_gradient(loss1) #non_trainable
static_loss2 = K.stop_gradient(loss2) #non_trainable
a1 = self.weight #trainable
a2 = 1 - a1 #trainable
static_a1 = K.stop_gradient(a1) #non_trainable
static_a2 = 1 - static_a1 #non_trainable
#this trains only alpha to minimize the difference between both losses
alpha_loss = K.square((a1 * static_loss1) - (a2 * static_loss2))
#or K.abs (.....)
#this trains only the original model weights to minimize both original losses
model_loss = (static_a1 * loss1) + (static_a2 * loss2)
return alpha_loss + model_loss
def compute_output_shape(self,inputShape):
return inputShape[0]
Notice that there is a custom constraint to keep this weight between 0 and 1. This constraint is implemented with:
class Between(Constraint):
def __init__(self,min_value,max_value):
self.min_value = min_value
self.max_value = max_value
def __call__(self,w):
return K.clip(w,self.min_value, self.max_value)
def get_config(self):
return {'min_value': self.min_value,
'max_value': self.max_value}
The training model
This model will take the prediction model as base, add the loss calculations and loss weighter at the end and output only the loss value. Because it outputs only a loss, we will use the true targets as inputs, and a dummy loss function defined like:
def ignoreLoss(true,pred):
return pred #this just tries to minimize the prediction without any extra computation
Model inputs:
#true targets
trueImg = Input((3,3,1))
trueClass = Input((2,))
#predictions from the prediction model
predImg = predictionModel.outputs[0]
predClass = predictionModel.outputs[1]
Model outputs = losses:
imageLoss = Lambda(calcImgLoss, name='loss_loc')([trueImg, predImg])
classLoss = Lambda(calcClassLoss, name='loss_cls')([trueClass, predClass])
weightedLoss = LossWeighter(name='weighted_loss')([imageLoss,classLoss])
Model:
trainingModel = Model([predictionModel.input, trueImg, trueClass], weightedLoss)
trainingModel.compile(optimizer='sgd', loss=ignoreLoss)
Dummy training
inputImages = np.zeros((7,5,5,2))
outputImages = np.ones((7,3,3,1))
outputClasses = np.ones((7,2))
dummyOut = np.zeros((7,))
trainingModel.fit([inputImages,outputImages,outputClasses], dummyOut, epochs = 50)
predictionModel.predict(inputImages)
Necessary imports
from keras.layers import *
from keras.models import Model
from keras.constraints import Constraint
from keras.initializers import Constant
from keras.losses import binary_crossentropy #or another you need
(EDIT) Explaining the problem with the old answer:
The formula used in the old answer would make alpha always go to 0 or 1, meaning only the smallest of the two losses would be ever trained. (Useless)
A new formula leads alpha to make both losses have the same value. Alpha would be trained properly and not tend to 0 or 1. But, still, the losses would not be properly trained because "increasing one loss to reach the other" would be a possibility for the model, and once both losses were equal, the model would stop training.
The new solution is a mix of the two proposals above, while the first actually trains the losses but with wrong alpha; and the second trains alpha with wrong losses. The mixed solution adds both, but uses K.stop_gradient to prevent the wrong part of the training from happening.
The result of this will be: the "easiest" loss (not the biggest) will be more trained than the hardest. We may use K.abs or K.square, as compared to "mae" or "mse" between the two losses. The best option is up to experiment.
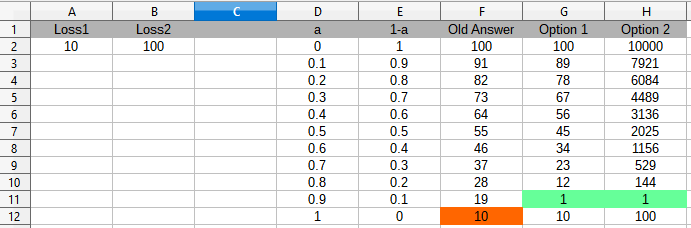
See this table comparing the old and new proposals:
![Table comparing solutions]()
This does not guarantee the best optimization though!!!
Training the easiest loss will not always have the best result, though. It may be better than favoring a huge loss just because it's formula is different. But the expected result might still need some manual weighting of the losses.
I fear there is no automatic training for this weight. If you have a target metric, you can try to train this metric (when possible, but metrics that depend on sorting, getting an index, rounding or anything that breaks backpropagation may not be possible to be transformed in losses).