I've a table of 860M rows in Google Cloud Spanner and I'm trying to understand how explanation works.
The table has a string column geoid and there is an index at this column.
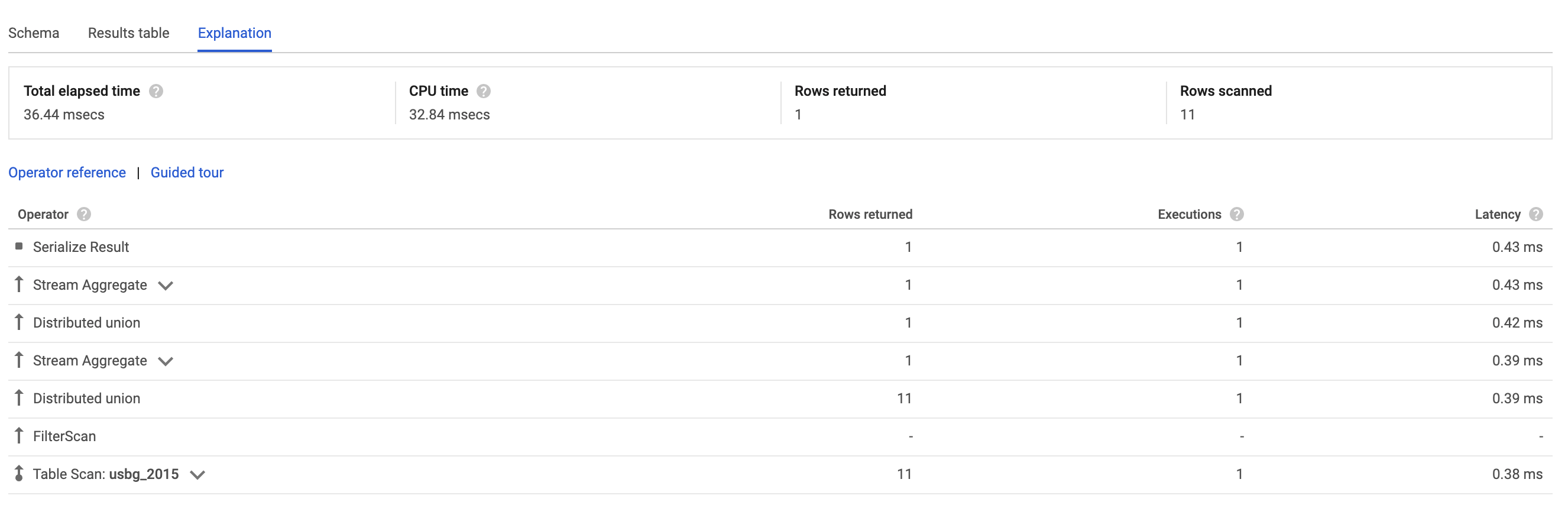
When I run the following query it takes only 36ms:
SELECT count(*)
FROM usbg_2015
WHERE geoid= '340170175001'
Table structure is:
CREATE TABLE usbg_2015 (
geoid STRING(12),
quadkey STRING(24),
) PRIMARY KEY (geoid, quadkey)
However, I don't understand why the explanation says it uses a Table Scan instead of an Index Scan. I understood a Table scan as a full scan of the table, in this case reading 860M rows and it should take more time than 36ms. What I'm missing?