How can use fuzzy matching in pandas to detect duplicate rows (efficiently)
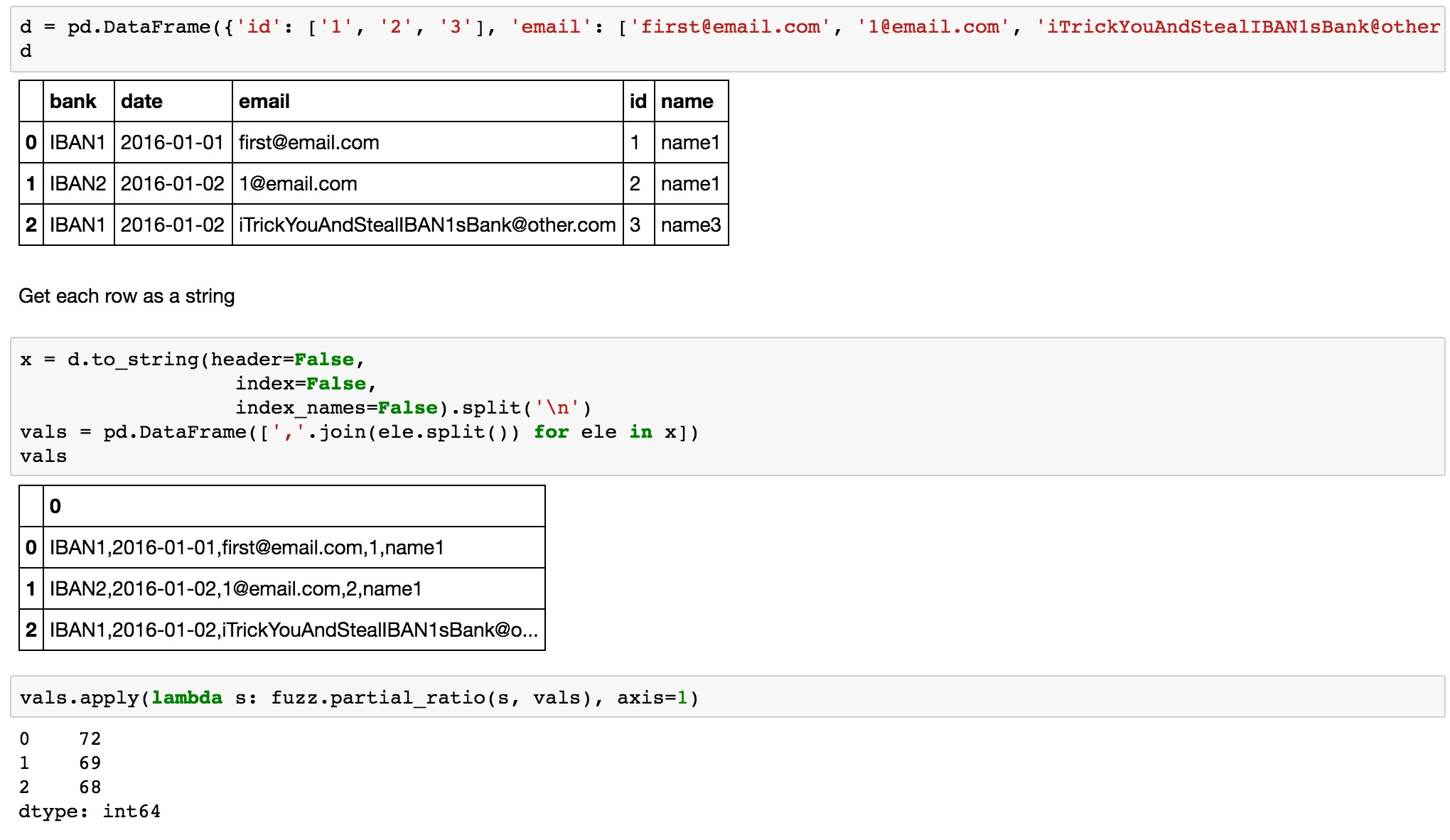
How to find duplicates of one column vs. all the other ones without a gigantic for loop of converting row_i toString() and then comparing it to all the other ones?
How can use fuzzy matching in pandas to detect duplicate rows (efficiently)
How to find duplicates of one column vs. all the other ones without a gigantic for loop of converting row_i toString() and then comparing it to all the other ones?
Not pandas specific, but within the python ecosystem the dedupe python library would seem to do what you want. In particular, it allows you to compare each column of a row separately and then combine the information into a single probability score of a match.
pandas-dedupe is your friend here. You can try to do the following:
import pandas as pd
from pandas_deudpe import dedupe_dataframe
df = pd.DataFrame.from_dict({'bank':['bankA', 'bankA', 'bankB', 'bankX'],'email':['email1', 'email1', 'email2', 'email3'],'name':['jon', 'john', 'mark', 'pluto']})
dd = dedupe_dataframe(df, ['bank', 'name', 'email'], sample_size=1)
If you also want to set a canonical name to same entitites, set canonicalize=True.
[I'm one of pandas-dedupe contributors]
There is now a package to make it easier to use the dedupe library with pandas: pandas-dedupe
(I am a developer of the original dedupe library, but not the pandas-dedupe package)
© 2022 - 2024 — McMap. All rights reserved.