There are two servers. The first is ERP system on production. The second one is the BI server for heavy analytical queries. We update the BI server on a daily basis via backups. However, it's not enough, some users want to see their data changes more often than the next day. I have no access to the ERP server and can't do anything, except asking for backups or replications.
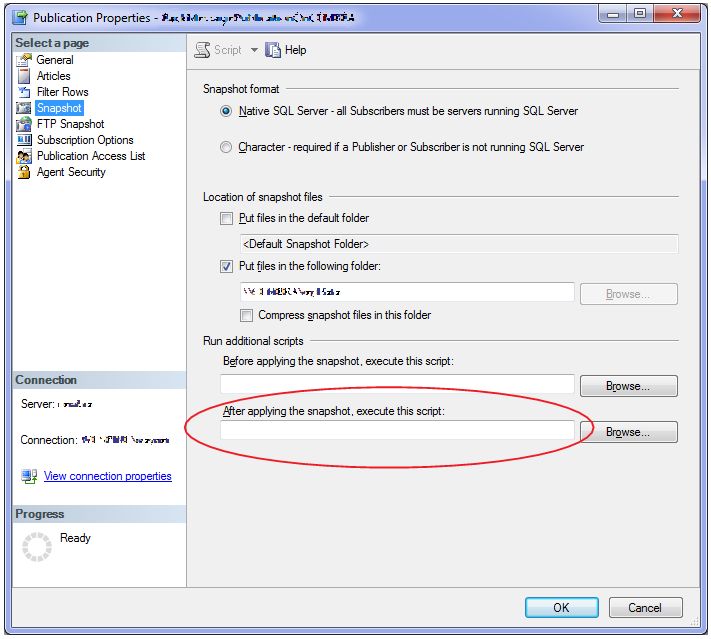
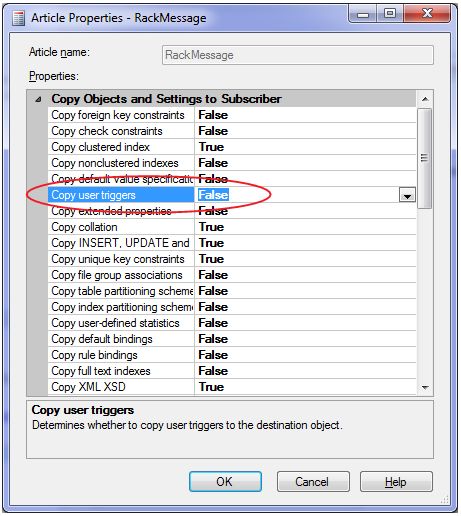
Before starting to ask for the replication. I want to understand if it's possible to use subscriber triggers in order to process not all the data, but changed. There is an ETL process to make some queries faster (indexing, transformation, etc). Triggers should do the trick, but I can't find a way to use them on the subscriber side only. The ERP system doesn't allow to make any changes on the DB level. So, the subscriber database seems to be fine for triggers (they don't affect on the ERP server performance). Nonetheless, I can't find a way to set them up. Processing all the data is an insane overhead.
Use case: Simplified example, say, we have two replicated tables:
+------------+-------------+--------+
| dt | customer_id | amount |
+------------+-------------+--------+
| 2017-01-01 | 1 | 234 |
| 2017-01-02 | 1 | 123 |
+------------+-------------+--------+
+------------+-------------+------------+------------+
| manager_id | customer_id | date_from | date_to |
+------------+-------------+------------+------------+
| 1 | 1 | 2017-01-01 | 2017-01-02 |
| 2 | 1 | 2017-01-02 | null |
+------------+-------------+------------+------------+
I need to transform them into the following indexed table:
+----------+-------------+------------+--------+
| dt_id | customer_id | manager_id | amount |
+----------+-------------+------------+--------+
| 20170101 | 1 | 1 | 234 |
| 20170102 | 1 | 2 | 123 |
+----------+-------------+------------+--------+
So, I created yet another database where I store the table above. Now, in order to update the table I have to truncate it and reinsert all the data again. I may join them all the in order to check the diffs, but it's too heavy for big tables as well. The trigger helps to track only changing records. The first input table can use a trigger:
create trigger SaleInsert
on Table1
after insert
begin
insert into NewDB..IndexedTable
select
//some transformation
from inserted
left join Table2
on Table1.customer_id = Table2.customer_id
and Table1.dt >= Table2.date_from
and Table1.dt < Table2.date_to
end
The same idea for update, delete, a similar approach for the second table. I could get automatically updated DWH with little lags. Yeah, I expect performance lags for high-loaded databases. Theoretically, it should work smoothly on servers with the same configurations.
But, again, there are no triggers on the subscriber side only. Any ideas, alternatives?