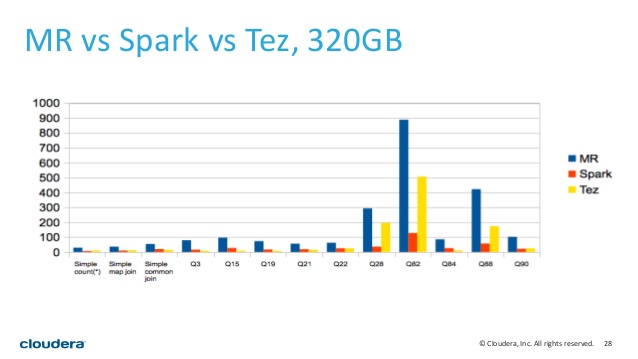
After reading What is hive, Is it a database?, a colleague yesterday mentioned that he was able to filter a 15B table, join it with another table after doing a "group by", which resulted in 6B records, in only 10 minutes! I wonder if this would be slower in Spark, since now with the DataFrames, they may be comparable, but I am not sure, thus the question.
Is Hive faster than Spark? Or this question doesn't have meaning? Sorry, for my ignorance.
He uses the latest Hive, which from seems to be using Tez.