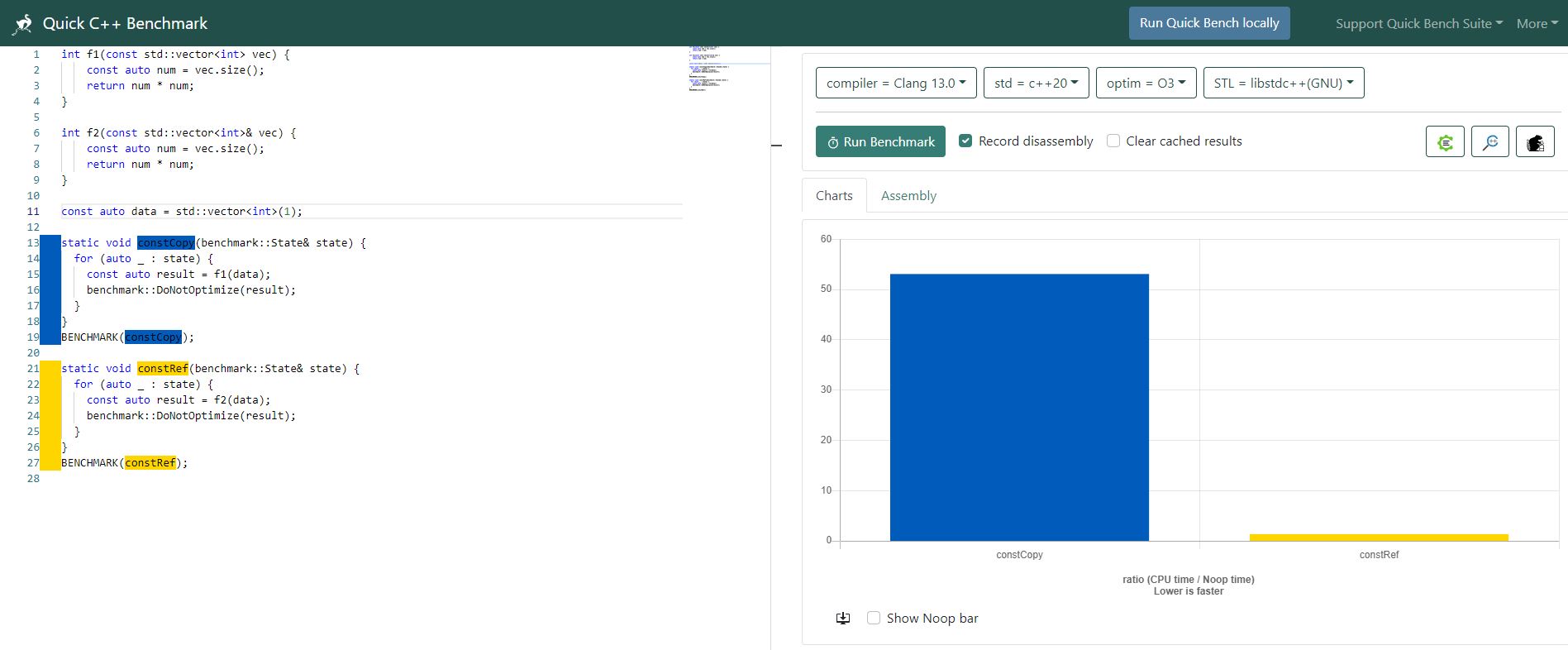
Looking at the assembly of the functions f1 and f2 won't work. With optimizations enabled they are likely to look completely identical. (Except that in some ABIs it is the callee's responsibility to destroy function parameters, in which case f1 will look much longer. But that doesn't mean anything by itself. There will be destruction of any created object somewhere anyway, whether in the caller or the callee.)
The performance difference here doesn't lie inside the function, but in the potential caller.
Function parameters are constructed in the context of the caller, not in the context of the callee. So, here if f1 is called like
std::vector<int> vec{/*...*/};
auto res = f1(vec);
will cause vec to be copied into the function parameter in the caller. It is not possible to elide the copy. (Of course the compiler is free to optimize the copy away if it can see that doing so won't change the observable behavior of the program, but that generally can't happen if the function isn't inlined, for example because it's definition is in another translation unit and there is no link-time optimization.)
With
std::vector<int> vec{/*...*/};
auto res = f2(vec);
no copy is done, even conceptually. Copy elision is not relevant.
It is true that e.g.
std::vector<int> vec{/*...*/};
auto res = f1(std::move(vec));
will use the move constructor and will generally be cheap enough that it might be faster than using f2 under some circumstances where the function can't be inlined. (However that will depend on how the ABI specifies that a std::vector is passed to functions as well.)
It is also true that e.g.
auto res = f1(std::vector<int>{/*...*/});
will construct only one std::vector<int> if copy elision is applied (guaranteed since C++17 and optionally before). However, the same is true if f2 was used.
In some situations f1 might be a better choice, because the compiler can be sure that it doesn't modify vec from the caller. (A const reference does not strictly mean that the referenced object can't be modified.) This may allow the compiler to make some optimizations in the caller without having to analyze the body of f1 that it might not be able to do with f2.
So all in all I would say, in some circumstances they are equally good, in some circumstances f2 is definitively the better choice and in some more rare situations it might be that f1 is the better choice. I would go with f2 by default.
However, looking at the bigger picture, I would try to avoid having a function which iterates over a vector take the vector itself as parameter. Functions like this can typically be written more generally to apply to arbitrary ranges and hence it would probably be easy to make them templates and use either the iterator interface or the C++20 range interface used by standard library algorithms. This way, if in the future someone decides to use some other container than std::vector, the function will still just work.