Whilst starting to learn lisp, I've come across the term tail-recursive. What does it mean exactly?
What is tail recursion?
Maybe it is late, but this is a pretty good article about tail recursive:programmerinterview.com/index.php/recursion/tail-recursion –
Instrumentalism
One of the great benefits of identifying a tail-recursive function is that it can be converted into an iterative form and thus reliving the algorithm from method-stack-overhead. Might like to visit response from @Kyle Cronin and few others below –
Chainman
Could someone tell me, Do merge sort and quick sort use tail recursion (TRO) ? –
Plumbery
@Plumbery - that's depends on the particular implementation of those (and any other) algorithms. –
Serpens
youtube.com/watch?v=-PX0BV9hGZY =) –
Cordeliacordelie
There is a very explaination here: youtu.be/KdlmSpjU-AE You can find Tail recursion at the end of the discussion. –
Eleonoraeleonore
writing a comment on a 14 year old tail recursion post could be considered "chasing tail" –
Rascality
Consider a simple function that adds the first N natural numbers. (e.g. sum(5) = 0 + 1 + 2 + 3 + 4 + 5 = 15).
Here is a simple JavaScript implementation that uses recursion:
function recsum(x) {
if (x === 0) {
return 0;
} else {
return x + recsum(x - 1);
}
}
If you called recsum(5), this is what the JavaScript interpreter would evaluate:
recsum(5)
5 + recsum(4)
5 + (4 + recsum(3))
5 + (4 + (3 + recsum(2)))
5 + (4 + (3 + (2 + recsum(1))))
5 + (4 + (3 + (2 + (1 + recsum(0)))))
5 + (4 + (3 + (2 + (1 + 0))))
5 + (4 + (3 + (2 + 1)))
5 + (4 + (3 + 3))
5 + (4 + 6)
5 + 10
15
Note how every recursive call has to complete before the JavaScript interpreter begins to actually do the work of calculating the sum.
Here's a tail-recursive version of the same function:
function tailrecsum(x, running_total = 0) {
if (x === 0) {
return running_total;
} else {
return tailrecsum(x - 1, running_total + x);
}
}
Here's the sequence of events that would occur if you called tailrecsum(5), (which would effectively be tailrecsum(5, 0), because of the default second argument).
tailrecsum(5, 0)
tailrecsum(4, 5)
tailrecsum(3, 9)
tailrecsum(2, 12)
tailrecsum(1, 14)
tailrecsum(0, 15)
15
In the tail-recursive case, with each evaluation of the recursive call, the running_total is updated.
Note: The original answer used examples from Python. These have been changed to JavaScript, since Python interpreters don't support tail call optimization. However, while tail call optimization is part of the ECMAScript 2015 spec, most JavaScript interpreters don't support it.
Can I say that with tail recursion the final answer is calculated by the LAST invocation of the method alone? If it is NOT tail recursion you need all the results for all method to calculate the answer. –
Redbird
Here's an addendum that presents a few examples in Lua: lua.org/pil/6.3.html May be useful to go through that as well! :) –
Erotic
Can someone please address chrisapotek's question? I'm confused how
tail recursion can be achieved in a language that doesn't optimize away tail calls. –
Gaudet @KevinMeredith "tail recursion" means that the last statement in a function, is a recursive call to the same function. You are correct that there is no point in doing this in a language that doesn't optimize away that recursion. Nevertheless, this answer does show the concept (almost) correctly. It would have been more clearly a tail call, if the "else:" were omitted. Wouldn't change the behavior, but would place the tail call as an independent statement. I will submit that as an edit. –
Seigniorage
@Seigniorage is correct. Tail recursion is recursion in tail position even when the underlying runtime/compiler does not do TCO. BTW: Including
else is better since then the whole if is a tail expression. –
Billfold So in python there is no advantage because with every call to tailrecsum function, a new stack frame is created - right? –
Remex
Re the note at the end of the answer: Only JavaScriptCore (from Apple) implements TCO, V8 (in Chrome, Chromium, Node.js, ...), SpiderMonkey (Firefox, etc.), and Chakra (Edge, for now) do not and don't plan to, even though it's in the specification. So on the desktop, only Safari has TCO. (On iOS, Chrome and Firefox and other browsers do because they're forced to use JavaScriptCore instead of their own engines, because non-Apple apps can't allocate executable memory. V8's adding an interpreter-only mode which they may switch to, but...) –
Sclater
Your answer perfectly describes the solution, and thanks. However JAVAScript is not a good language to showcase such answer. Because tail recursion has two parts, compiler shall optimize the modified code beside developer's modification to make a recursive function a tail recursive one. I would rather choose a modern language such as Scala if I were you. Anyway thanks for your detailed explanation. –
Mahla
but why is such a procedure called tail recursion and not e.g. head recursion? –
Drier
Is
tailrecsum better than recsum in some way? If so, how? (I suppose it's better, since it's slightly more complicated but still important enough to talk about.) –
Perspex In traditional recursion, the typical model is that you perform your recursive calls first, and then you take the return value of the recursive call and calculate the result. In this manner, you don't get the result of your calculation until you have returned from every recursive call.
In tail recursion, you perform your calculations first, and then you execute the recursive call, passing the results of your current step to the next recursive step. This results in the last statement being in the form of (return (recursive-function params)). Basically, the return value of any given recursive step is the same as the return value of the next recursive call.
The consequence of this is that once you are ready to perform your next recursive step, you don't need the current stack frame any more. This allows for some optimization. In fact, with an appropriately written compiler, you should never have a stack overflow snicker with a tail recursive call. Simply reuse the current stack frame for the next recursive step. I'm pretty sure Lisp does this.
"I'm pretty sure Lisp does this" -- Scheme does, but Common Lisp doesn't always. –
Francesco
@Daniel "Basically, the return value of any given recursive step is the same as the return value of the next recursive call."- I fail to see this argument holding true for the code snippet posted by Lorin Hochstein. Can you please elaborate? –
Sucker
@Sucker This is a really late response, but that is actually true in Lorin Hochstein's example. The calculation for each step is done before the recursive call, rather than after it. As a result, each stop just returns the value directly from the previous step. The last recursive call finishes the computation and then returns the final result unmodified all the way back down the call stack. –
Amadavat
Scala does but you need the @tailrec specified to enforce it. –
Vevina
"In this manner, you don't get the result of your calculation until you have returned from every recursive call." -- maybe I misunderstood this, but this isn't particularly true for lazy languages where the traditional recursion is the only way to actually get a result without calling all recursions (e.g. folding over an infinite list of Bools with &&). –
Mcdade
@SilentDirge. Scala does it by default. The tailrec annotation is only to be sure it fails during compilation if it's not TCO'd. –
Cantone
stack frame reuse turns out to be orthogonal to TCO itself. main thing is the jump and that the frame is discarded. in case of tail call to self it can be reused, but in case of more general tail calls, or even in mutual tail-recursion of several functions, reusing the stack frame can be tough to achieve, if not downright impossible. –
Cassicassia
That last paragraph was crucial for me: tail-recursivity allows us to reuse stack frames –
Drawer
but why is such a procedure called tail recursion and not e.g. head recursion? –
Drier
The last paragraph in the answer, "The consequence of this..." is the heart of why folks talk about tail recursion so much: a recursive algorithm or function is easy to read and to reason through. But it is normally horrible for memory consumption. With tail recursion and the dump of the stack, you get better readability and reasoning -- hence better code quality -- while still getting good performance. Yay! :smiley: –
Beanery
An important point is that tail recursion is essentially equivalent to looping. It's not just a matter of compiler optimization, but a fundamental fact about expressiveness. This goes both ways: you can take any loop of the form
while(E) { S }; return Q
where E and Q are expressions and S is a sequence of statements, and turn it into a tail recursive function
f() = if E then { S; return f() } else { return Q }
Of course, E, S, and Q have to be defined to compute some interesting value over some variables. For example, the looping function
sum(n) {
int i = 1, k = 0;
while( i <= n ) {
k += i;
++i;
}
return k;
}
is equivalent to the tail-recursive function(s)
sum_aux(n,i,k) {
if( i <= n ) {
return sum_aux(n,i+1,k+i);
} else {
return k;
}
}
sum(n) {
return sum_aux(n,1,0);
}
(This "wrapping" of the tail-recursive function with a function with fewer parameters is a common functional idiom.)
In the answer by @LorinHochstein I understood, based on his explanation, that tail recursion to be when the recursive portion follows "Return", however in yours, the tail recursive is not. Are you sure your example is properly considered tail recursion? –
Strawworm
@Imray The tail-recursive part is the "return sum_aux" statement inside sum_aux. –
Sarazen
@lmray: Chris's code is essentially equivalent. The order of the if/then and style of the limiting test...if x == 0 versus if(i<=n)...is not something to get hung up on. The point is that each iteration passes its result to the next. –
Bucko
else { return k; } can be changed to return k; –
Inpour @cOder, you're right but people come to stackoverflow to also learn then maybe use of
if and else make it more comprehensive for more beginners, I think –
Maecenas but why is such a procedure called tail recursion and not e.g. head recursion? –
Drier
This excerpt from the book Programming in Lua shows how to make a proper tail recursion (in Lua, but should apply to Lisp too) and why it's better.
A tail call [tail recursion] is a kind of goto dressed as a call. A tail call happens when a function calls another as its last action, so it has nothing else to do. For instance, in the following code, the call to
gis a tail call:function f (x) return g(x) endAfter
fcallsg, it has nothing else to do. In such situations, the program does not need to return to the calling function when the called function ends. Therefore, after the tail call, the program does not need to keep any information about the calling function in the stack. ...Because a proper tail call uses no stack space, there is no limit on the number of "nested" tail calls that a program can make. For instance, we can call the following function with any number as argument; it will never overflow the stack:
function foo (n) if n > 0 then return foo(n - 1) end end... As I said earlier, a tail call is a kind of goto. As such, a quite useful application of proper tail calls in Lua is for programming state machines. Such applications can represent each state by a function; to change state is to go to (or to call) a specific function. As an example, let us consider a simple maze game. The maze has several rooms, each with up to four doors: north, south, east, and west. At each step, the user enters a movement direction. If there is a door in that direction, the user goes to the corresponding room; otherwise, the program prints a warning. The goal is to go from an initial room to a final room.
This game is a typical state machine, where the current room is the state. We can implement such maze with one function for each room. We use tail calls to move from one room to another. A small maze with four rooms could look like this:
function room1 () local move = io.read() if move == "south" then return room3() elseif move == "east" then return room2() else print("invalid move") return room1() -- stay in the same room end end function room2 () local move = io.read() if move == "south" then return room4() elseif move == "west" then return room1() else print("invalid move") return room2() end end function room3 () local move = io.read() if move == "north" then return room1() elseif move == "east" then return room4() else print("invalid move") return room3() end end function room4 () print("congratulations!") end
So you see, when you make a recursive call like:
function x(n)
if n==0 then return 0
n= n-2
return x(n) + 1
end
This is not tail recursive because you still have things to do (add 1) in that function after the recursive call is made. If you input a very high number it will probably cause a stack overflow.
This is a great answer because it explains the implications of tail calls upon stack size. –
Inherit
@AndrewSwan Indeed, although I believe that the original asker and the occasional reader who might stumble into this question might be better served with the accepted answer (since he might not know what the stack actually is.) By the way I use Jira, big fan. –
Pasteur
My favourite answer as well due to including the implication for the stack size. –
Astonishment
Using regular recursion, each recursive call pushes another entry onto the call stack. When the recursion is completed, the app then has to pop each entry off all the way back down.
With tail recursion, depending on language the compiler may be able to collapse the stack down to one entry, so you save stack space...A large recursive query can actually cause a stack overflow.
Basically Tail recursions are able to be optimized into iteration.
the "A large recursive query can actually cause a stack overflow." should be in the 1st paragraph, not in the 2nd (tail recursion) one ? The big advantage of tail recursion is that it can be (ex: Scheme) optimized in such a way as not to "accumulate" calls in the stack, so will mostly avoid stack overflows! –
Sadirah
The jargon file has this to say about the definition of tail recursion:
tail recursion /n./
If you aren't sick of it already, see tail recursion.
Interestingly enough, the jargon file entry is actually a valid example of tail recursion. Once you satisfy the condition of being sick of tail recursion, you don't have to traverse back down the stack of previous times you went to the definition of tail recursion in order to complete your understanding of the definition. You are free to exit the definition directly and move on with your life. –
Postnatal
Instead of explaining it with words, here's an example. This is a Scheme version of the factorial function:
(define (factorial x)
(if (= x 0) 1
(* x (factorial (- x 1)))))
Here is a version of factorial that is tail-recursive:
(define factorial
(letrec ((fact (lambda (x accum)
(if (= x 0) accum
(fact (- x 1) (* accum x))))))
(lambda (x)
(fact x 1))))
You will notice in the first version that the recursive call to fact is fed into the multiplication expression, and therefore the state has to be saved on the stack when making the recursive call. In the tail-recursive version there is no other S-expression waiting for the value of the recursive call, and since there is no further work to do, the state doesn't have to be saved on the stack. As a rule, Scheme tail-recursive functions use constant stack space.
+1 for mentioning the most important aspect of tail-recursions that they can be converted into an iterative form and thereby turning it into an O(1) memory complexity form. –
Chainman
@Chainman not exactly; the answer correctly speaks about "constant stack space", not memory in general. not to be nitpicking, just to make sure there's no misunderstanding. e.g. tail-recursive list-tail-mutating
list-reverse procedure will run in constant stack space but will create and grow a data structure on the heap. A tree traversal could use a simulated stack, in an additional argument. etc. –
Cassicassia Tail recursion refers to the recursive call being last in the last logic instruction in the recursive algorithm.
Typically in recursion, you have a base-case which is what stops the recursive calls and begins popping the call stack. To use a classic example, though more C-ish than Lisp, the factorial function illustrates tail recursion. The recursive call occurs after checking the base-case condition.
factorial(x, fac=1) {
if (x == 1)
return fac;
else
return factorial(x-1, x*fac);
}
The initial call to factorial would be factorial(n) where fac=1 (default value) and n is the number for which the factorial is to be calculated.
I found your explanation easiest to understand, but if it's anything to go by, then tail recursion is only useful for functions with one statement base cases. Consider a method such as this postimg.cc/5Yg3Cdjn. Note: the outer
else is the step you might call a "base case" but spans across several lines. Am I misunderstanding you or is my assumption correct? Tail recursion is only good for one liners? –
Expedition @IWantAnswers - No, the body of the function can be arbitrarily large. All that's required for a tail call is that the branch it's in calls the function as the very last thing it does, and returns the result of calling the function. The
factorial example is just the classic simple example, that's all. –
Sclater Peter Meyer, for your example, does the runtime really need to maintain a call stack? @Cranio –
Brosy
It means that rather than needing to push the instruction pointer on the stack, you can simply jump to the top of a recursive function and continue execution. This allows for functions to recurse indefinitely without overflowing the stack.
I wrote a blog post on the subject, which has graphical examples of what the stack frames look like.
The best way for me to understand tail call recursion is a special case of recursion where the last call(or the tail call) is the function itself.
Comparing the examples provided in Python:
def recsum(x):
if x == 1:
return x
else:
return x + recsum(x - 1)
^RECURSION
def tailrecsum(x, running_total=0):
if x == 0:
return running_total
else:
return tailrecsum(x - 1, running_total + x)
^TAIL RECURSION
As you can see in the general recursive version, the final call in the code block is x + recsum(x - 1). So after calling the recsum method, there is another operation which is x + ...
However, in the tail recursive version, the final call(or the tail call) in the code block is tailrecsum(x - 1, running_total + x) which means the last call is made to the method itself and no operation after that.
This point is important because tail recursion as seen here is not making the memory grow because when the underlying VM sees a function calling itself in a tail position (the last expression to be evaluated in a function), it eliminates the current stack frame, which is known as Tail Call Optimization(TCO).
EDIT
NB. Do bear in mind that the example above is written in Python whose runtime does not support TCO. This is just an example to explain the point. TCO is supported in languages like Scheme, Haskell etc
Here is a quick code snippet comparing two functions. The first is traditional recursion for finding the factorial of a given number. The second uses tail recursion.
Very simple and intuitive to understand.
An easy way to tell if a recursive function is a tail recursive is if it returns a concrete value in the base case. Meaning that it doesn't return 1 or true or anything like that. It will more than likely return some variant of one of the method parameters.
Another way is to tell is if the recursive call is free of any addition, arithmetic, modification, etc... Meaning its nothing but a pure recursive call.
public static int factorial(int mynumber) {
if (mynumber == 1) {
return 1;
} else {
return mynumber * factorial(--mynumber);
}
}
public static int tail_factorial(int mynumber, int sofar) {
if (mynumber == 1) {
return sofar;
} else {
return tail_factorial(--mynumber, sofar * mynumber);
}
}
0! is 1. So "mynumber == 1" should be "mynumber == 0". –
Laurentian
The recursive function is a function which calls by itself
It allows programmers to write efficient programs using a minimal amount of code.
The downside is that they can cause infinite loops and other unexpected results if not written properly.
I will explain both Simple Recursive function and Tail Recursive function
In order to write a Simple recursive function
- The first point to consider is when should you decide on coming out of the loop which is the if loop
- The second is what process to do if we are our own function
From the given example:
public static int fact(int n){
if(n <=1)
return 1;
else
return n * fact(n-1);
}
From the above example
if(n <=1)
return 1;
Is the deciding factor when to exit the loop
else
return n * fact(n-1);
Is the actual processing to be done
Let me the break the task one by one for easy understanding.
Let us see what happens internally if I run fact(4)
- Substituting n=4
public static int fact(4){
if(4 <=1)
return 1;
else
return 4 * fact(4-1);
}
If loop fails so it goes to else loop
so it returns 4 * fact(3)
In stack memory, we have
4 * fact(3)Substituting n=3
public static int fact(3){
if(3 <=1)
return 1;
else
return 3 * fact(3-1);
}
If loop fails so it goes to else loop
so it returns 3 * fact(2)
Remember we called ```4 * fact(3)``
The output for fact(3) = 3 * fact(2)
So far the stack has 4 * fact(3) = 4 * 3 * fact(2)
In stack memory, we have
4 * 3 * fact(2)Substituting n=2
public static int fact(2){
if(2 <=1)
return 1;
else
return 2 * fact(2-1);
}
If loop fails so it goes to else loop
so it returns 2 * fact(1)
Remember we called 4 * 3 * fact(2)
The output for fact(2) = 2 * fact(1)
So far the stack has 4 * 3 * fact(2) = 4 * 3 * 2 * fact(1)
In stack memory, we have
4 * 3 * 2 * fact(1)Substituting n=1
public static int fact(1){
if(1 <=1)
return 1;
else
return 1 * fact(1-1);
}
If loop is true
so it returns 1
Remember we called 4 * 3 * 2 * fact(1)
The output for fact(1) = 1
So far the stack has 4 * 3 * 2 * fact(1) = 4 * 3 * 2 * 1
Finally, the result of fact(4) = 4 * 3 * 2 * 1 = 24
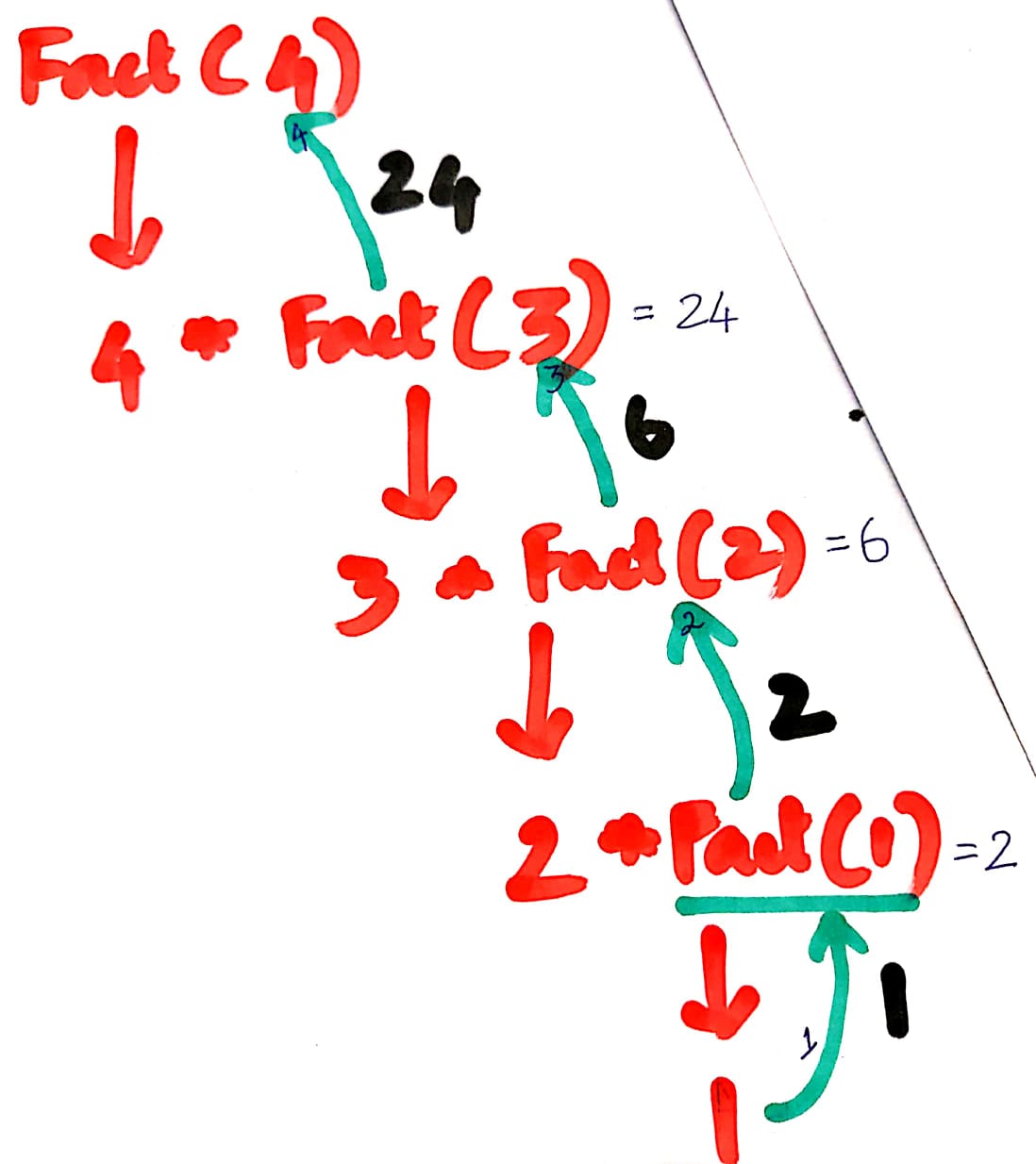
The Tail Recursion would be
public static int fact(x, running_total=1) {
if (x==1) {
return running_total;
} else {
return fact(x-1, running_total*x);
}
}
- Substituting n=4
public static int fact(4, running_total=1) {
if (x==1) {
return running_total;
} else {
return fact(4-1, running_total*4);
}
}
If loop fails so it goes to else loop
so it returns fact(3, 4)
In stack memory, we have
fact(3, 4)Substituting n=3
public static int fact(3, running_total=4) {
if (x==1) {
return running_total;
} else {
return fact(3-1, 4*3);
}
}
If loop fails so it goes to else loop
so it returns fact(2, 12)
In stack memory, we have
fact(2, 12)Substituting n=2
public static int fact(2, running_total=12) {
if (x==1) {
return running_total;
} else {
return fact(2-1, 12*2);
}
}
If loop fails so it goes to else loop
so it returns fact(1, 24)
In stack memory, we have
fact(1, 24)Substituting n=1
public static int fact(1, running_total=24) {
if (x==1) {
return running_total;
} else {
return fact(1-1, 24*1);
}
}
If loop is true
so it returns running_total
The output for running_total = 24
Finally, the result of fact(4,1) = 24
you should probably mention what language you code is in. –
Deceleron
A tail recursive function is a recursive function where the last operation it does before returning is make the recursive function call. That is, the return value of the recursive function call is immediately returned. For example, your code would look like this:
def recursiveFunction(some_params):
# some code here
return recursiveFunction(some_args)
# no code after the return statement
Compilers and interpreters that implement tail call optimization or tail call elimination can optimize recursive code to prevent stack overflows. If your compiler or interpreter doesn't implement tail call optimization (such as the CPython interpreter) there is no additional benefit to writing your code this way.
For example, this is a standard recursive factorial function in Python:
def factorial(number):
if number == 1:
# BASE CASE
return 1
else:
# RECURSIVE CASE
# Note that `number *` happens *after* the recursive call.
# This means that this is *not* tail call recursion.
return number * factorial(number - 1)
And this is a tail call recursive version of the factorial function:
def factorial(number, accumulator=1):
if number == 0:
# BASE CASE
return accumulator
else:
# RECURSIVE CASE
# There's no code after the recursive call.
# This is tail call recursion:
return factorial(number - 1, number * accumulator)
print(factorial(5))
(Note that even though this is Python code, the CPython interpreter doesn't do tail call optimization, so arranging your code like this confers no runtime benefit.)
You may have to make your code a bit more unreadable to make use of tail call optimization, as shown in the factorial example. (For example, the base case is now a bit unintuitive, and the accumulator parameter is effectively used as a sort of global variable.)
But the benefit of tail call optimization is that it prevents stack overflow errors. (I'll note that you can get this same benefit by using an iterative algorithm instead of a recursive one.)
Stack overflows are caused when the call stack has had too many frame objects pushed onto. A frame object is pushed onto the call stack when a function is called, and popped off the call stack when the function returns. Frame objects contain info such as local variables and what line of code to return to when the function returns.
If your recursive function makes too many recursive calls without returning, the call stack can exceed its frame object limit. (The number varies by platform; in Python it is 1000 frame objects by default.) This causes a stack overflow error. (Hey, that's where the name of this website comes from!)
However, if the last thing your recursive function does is make the recursive call and return its return value, then there's no reason it needs to keep the current frame object needs to stay on the call stack. After all, if there's no code after the recursive function call, there's no reason to hang on to the current frame object's local variables. So we can get rid of the current frame object immediately rather than keep it on the call stack. The end result of this is that your call stack doesn't grow in size, and thus cannot stack overflow.
A compiler or interpreter must have tail call optimization as a feature for it to be able to recognize when tail call optimization can be applied. Even then, you may have rearrange the code in your recursive function to make use of tail call optimization, and it's up to you if this potential decrease in readability is worth the optimization.
"Tail recursion (also called tail call optimization or tail call elimination)". No; tail-call elimination or tail-call optimization is something you can apply to a tail-recursive function, but they are not the same thing. You can write tail-recursive functions in Python (as you show), but they are no more efficient than a non-tail-recursive function, because Python does not perform tail-call optimization. –
Fbi
Does it mean that if someone manages to optimize the website and render the recursive call tail-recursive we would not have StackOverflow site anymore?! That's horrible. –
Footworn
this was the only example I understood the point of the definition. I got the stuff about popping the stack with non-tail recursion but you made the exercise explicit for me. thanks. –
Deceleron
I'm not a Lisp programmer, but I think this will help.
Basically it's a style of programming such that the recursive call is the last thing you do.
In Java, here's a possible tail recursive implementation of the Fibonacci function:
public int tailRecursive(final int n) {
if (n <= 2)
return 1;
return tailRecursiveAux(n, 1, 1);
}
private int tailRecursiveAux(int n, int iter, int acc) {
if (iter == n)
return acc;
return tailRecursiveAux(n, ++iter, acc + iter);
}
Contrast this with the standard recursive implementation:
public int recursive(final int n) {
if (n <= 2)
return 1;
return recursive(n - 1) + recursive(n - 2);
}
This is returning wrong results for me, for input 8 I get 36, it has to be 21. Am I missing something? I'm using java and copy pasted it. –
Viewy
This returns SUM(i) for i in [1, n]. Nothing to do with Fibbonacci. For a Fibbo, you need a tests which substracts
iter to acc when iter < (n-1). –
Denouement Here is a Common Lisp example that does factorials using tail-recursion. Due to the stack-less nature, one could perform insanely large factorial computations ...
(defun ! (n &optional (product 1))
(if (zerop n) product
(! (1- n) (* product n))))
And then for fun you could try (format nil "~R" (! 25))
A tail recursion is a recursive function where the function calls itself at the end ("tail") of the function in which no computation is done after the return of recursive call. Many compilers optimize to change a recursive call to a tail recursive or an iterative call.
Consider the problem of computing factorial of a number.
A straightforward approach would be:
factorial(n):
if n==0 then 1
else n*factorial(n-1)
Suppose you call factorial(4). The recursion tree would be:
factorial(4)
/ \
4 factorial(3)
/ \
3 factorial(2)
/ \
2 factorial(1)
/ \
1 factorial(0)
\
1
The maximum recursion depth in the above case is O(n).
However, consider the following example:
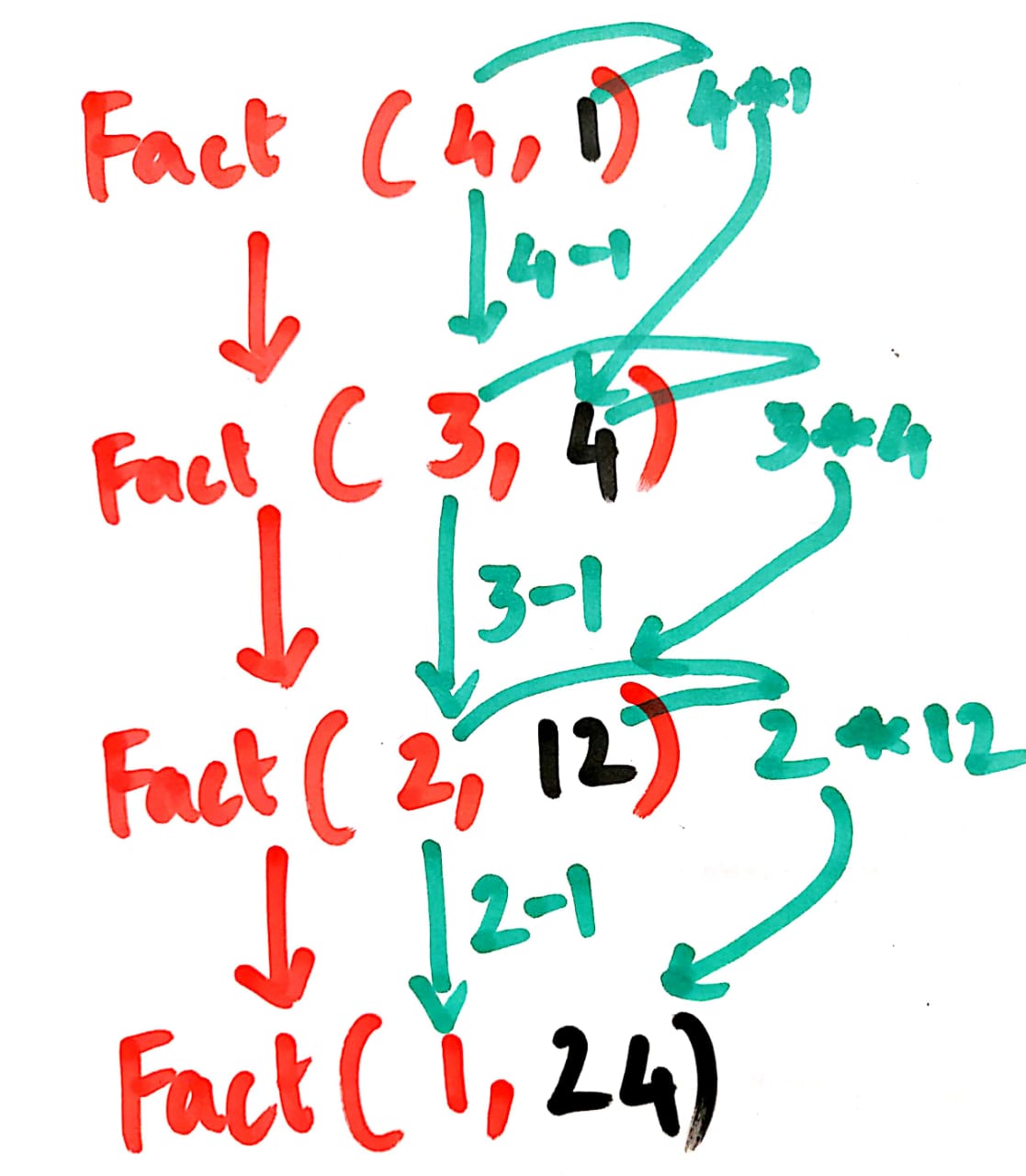
factAux(m,n):
if n==0 then m;
else factAux(m*n,n-1);
factTail(n):
return factAux(1,n);
Recursion tree for factTail(4) would be:
factTail(4)
|
factAux(1,4)
|
factAux(4,3)
|
factAux(12,2)
|
factAux(24,1)
|
factAux(24,0)
|
24
Here also, maximum recursion depth is O(n) but none of the calls adds any extra variable to the stack. Hence the compiler can do away with a stack.
In short, a tail recursion has the recursive call as the last statement in the function so that it doesn't have to wait for the recursive call.
So this is a tail recursion i.e. N(x - 1, p * x) is the last statement in the function where the compiler is clever to figure out that it can be optimised to a for-loop (factorial). The second parameter p carries the intermediate product value.
function N(x, p) {
return x == 1 ? p : N(x - 1, p * x);
}
This is the non-tail-recursive way of writing the above factorial function (although some C++ compilers may be able to optimise it anyway).
function N(x) {
return x == 1 ? 1 : x * N(x - 1);
}
but this is not:
function F(x) {
if (x == 1) return 0;
if (x == 2) return 1;
return F(x - 1) + F(x - 2);
}
I did write a long post titled "Understanding Tail Recursion – Visual Studio C++ – Assembly View"

How is your function N tail-recursive ? –
Digress
N(x-1) is the last statement in the function where the compiler is clever to figure out that it can be optimised to a for-loop (factorial) –
Flan
My concern is that your function N is exactly the function recsum from the accepted answer of this topic (except that it is a sum and not a product), and that recsum is said to be non tail-recursive ? –
Digress
Tail recursion is the life you are living right now. You constantly recycle the same stack frame, over and over, because there's no reason or means to return to a "previous" frame. The past is over and done with so it can be discarded. You get one frame, forever moving into the future, until your process inevitably dies.
The analogy breaks down when you consider some processes might utilize additional frames but are still considered tail-recursive if the stack does not grow infinitely.
it doesn't break under split personality disorder interpretation. :) A Society of Mind; a Mind as a Society. :) –
Cassicassia
Wow! Now thats another way to think about it –
Boleyn
This is an excerpt from Structure and Interpretation of Computer Programs about tail recursion.
In contrasting iteration and recursion, we must be careful not to confuse the notion of a recursive process with the notion of a recursive procedure. When we describe a procedure as recursive, we are referring to the syntactic fact that the procedure definition refers (either directly or indirectly) to the procedure itself. But when we describe a process as following a pattern that is, say, linearly recursive, we are speaking about how the process evolves, not about the syntax of how a procedure is written. It may seem disturbing that we refer to a recursive procedure such as fact-iter as generating an iterative process. However, the process really is iterative: Its state is captured completely by its three state variables, and an interpreter need keep track of only three variables in order to execute the process.
One reason that the distinction between process and procedure may be confusing is that most implementations of common languages (including Ada, Pascal, and C) are designed in such a way that the interpretation of any recursive procedure consumes an amount of memory that grows with the number of procedure calls, even when the process described is, in principle, iterative. As a consequence, these languages can describe iterative processes only by resorting to special-purpose “looping constructs” such as do, repeat, until, for, and while. The implementation of Scheme does not share this defect. It will execute an iterative process in constant space, even if the iterative process is described by a recursive procedure. An implementation with this property is called tail-recursive. With a tail-recursive implementation, iteration can be expressed using the ordinary procedure call mechanism, so that special iteration constructs are useful only as syntactic sugar.
I read through all answers here, and yet this is the most clear explanation which touches the really deep core of this concept. It explains it in such a straight way which makes everything looks so simple and so clear. Forgive my rudeness please. It somehow makes me feel like the other answers just do not hit the nail on the head. I think that is why SICP matters. –
Epanorthosis
here is a Perl 5 version of the tailrecsum function mentioned earlier.
sub tail_rec_sum($;$){
my( $x,$running_total ) = (@_,0);
return $running_total unless $x;
@_ = ($x-1,$running_total+$x);
goto &tail_rec_sum; # throw away current stack frame
}
Tail Recursion is pretty fast as compared to normal recursion. It is fast because the output of the ancestors call will not be written in stack to keep the track. But in normal recursion all the ancestor calls output written in stack to keep the track.
- Tail Recursive Function is a recursive function in which recursive call is the last executed thing in the function.
Regular recursive function, we have stack and everytime we invoke a recursive function within that recursive function, adds another layer to our call stack. In normal recursion
space: O(n) tail recursion makes space complexity from
O(N)=>O(1)
Tail call optimization means that it is possible to call a function from another function without growing the call stack.
We should write tail recursion in recursive solutions. but certain languages do not actually support the tail recursion in their engine that compiles the language down. since ecma6, there has been tail recursion that was in the specification. BUt none of the engines that compile js have implemented tail recursion into it. you wont achieve O(1) in js, because the compiler itself does not know how to implement this tail recursion. As of January 1, 2020 Safari is the only browser that supports tail call optimization.
Haskell and Java have tail recursion optimization
Regular Recursive Factorial
function Factorial(x) {
//Base case x<=1
if (x <= 1) {
return 1;
} else {
// x is waiting for the return value of Factorial(x-1)
// the last thing we do is NOT applying the recursive call
// after recursive call we still have to multiply.
return x * Factorial(x - 1);
}
}
we have 4 calls in our call stack.
Factorial(4); // waiting in the memory for Factorial(3)
4 * Factorial(3); // waiting in the memory for Factorial(2)
4 * (3 * Factorial(2)); // waiting in the memory for Factorial(1)
4 * (3 * (2 * Factorial(1)));
4 * (3 * (2 * 1));
- We are making 4 Factorial() calls, space is O(n)
- this mmight cause Stackoverflow
Tail Recursive Factorial
function tailFactorial(x, totalSoFar = 1) {
//Base Case: x===0. In recursion there must be base case. Otherwise they will never stop
if (x === 0) {
return totalSoFar;
} else {
// there is nothing waiting for tailFactorial to complete. we are returning another instance of tailFactorial()
// we are not doing any additional computaion with what we get back from this recursive call
return tailFactorial(x - 1, totalSoFar * x);
}
}
- We dont need to remember anything after we make our recursive call
A function is tail recursive if each recursive case consists only of a call to the function itself, possibly with different arguments. Or, tail recursion is recursion with no pending work. Note that this is a programming-language independent concept.
Consider the function defined as:
g(a, b, n) = a * b^n
A possible tail-recursive formulation is:
g(a, b, n) | n is zero = a
| n is odd = g(a*b, b, n-1)
| otherwise = g(a, b*b, n/2)
If you examine each RHS of g(...) that involves a recursive case, you'll find that the whole body of the RHS is a call to g(...), and only that. This definition is tail recursive.
For comparison, a non-tail-recursive formulation might be:
g'(a, b, n) = a * f(b, n)
f(b, n) | n is zero = 1
| n is odd = f(b, n-1) * b
| otherwise = f(b, n/2) ^ 2
Each recursive case in f(...) has some pending work that needs to happen after the recursive call.
Note that when we went from g' to g, we made essential use of associativity
(and commutativity) of multiplication. This is not an accident, and most cases where you will need to transform recursion to tail-recursion will make use of such properties: if we want to eagerly do some work rather than leave it pending, we have to use something like associativity to prove that the answer will be the same.
Tail recursive calls can be implemented with a backwards jump, as opposed to using a stack for normal recursive calls. Note that detecting a tail call, or emitting a backwards jump is usually straightforward. However, it is often hard to rearrange the arguments such that the backwards jump is possible. Since this optimization is not free, language implementations can choose not to implement this optimization, or require opt-in by marking recursive calls with a 'tailcall' instruction and/or choosing a higher optimization setting.
Some languages (e.g. Scheme) do, however, require all implementations to optimize tail-recursive functions, maybe even all calls in tail position.
Backwards jumps are usually abstracted as a (while) loop in most imperative languages, and tail-recursion, when optimized to a backwards jump, is isomorphic to looping.
so,
def f(x): f(x+1) is tail recursive, but def h(x): g(x+2) and def g(x): h(x-1) are not, by your definition. but I do think they too are TR. Scheme in particular requires all tail calls to be optimized, not just tail calls to self. (my example of mutually tail-recursive functions is somewhere in between). –
Cassicassia I think "recursive" usually means direct recursion, unless there is a "mutual" modifier. Somewhat relatedly, I'd expect that "tail-recursive calls" mean backwards jumps, while normal "tail calls" or "sibling calls" are used for general cross jumps. I expect "mutually tail-recursive" is somewhat unusual, and is probably sufficiently covered by "tail call" (both in semantics, and in implementation). –
Deirdredeism
I remember seeing a phrase somewhere "a function is (tail) recursive if there's a function call (in tail position) in it which eventually leads to this function being called again"... what's important, I think, is that when we say "tail recursive" we mean "can run in constant stack space" and mutual tail rec functions do certainly fall into this category. –
Cassicassia
I think we should separate the implementation aspect (stack space) from the definition. The usual mathematical definition of recursion is a "function defined in terms of itself", and if it indirectly defined, it is often termed as mutually recursive. I think it is useful to define tail recursion as recursion with no pending work (i.e. a backwards jump). I agree that for language definition, it is more beneficial to talk about all calls in tail position. –
Deirdredeism
@ Hari nice suggestion! –
Cassicassia
To understand some of the core differences between tail-call recursion and non-tail-call recursion we can explore the .NET implementations of these techniques.
Here is an article with some examples in C#, F#, and C++\CLI: Adventures in Tail Recursion in C#, F#, and C++\CLI.
C# does not optimize for tail-call recursion whereas F# does.
The differences of principle involve loops vs. Lambda calculus. C# is designed with loops in mind whereas F# is built from the principles of Lambda calculus. For a very good (and free) book on the principles of Lambda calculus, see Structure and Interpretation of Computer Programs, by Abelson, Sussman, and Sussman.
Regarding tail calls in F#, for a very good introductory article, see Detailed Introduction to Tail Calls in F#. Finally, here is an article that covers the difference between non-tail recursion and tail-call recursion (in F#): Tail-recursion vs. non-tail recursion in F sharp.
If you want to read about some of the design differences of tail-call recursion between C# and F#, see Generating Tail-Call Opcode in C# and F#.
If you care enough to want to know what conditions prevent the C# compiler from performing tail-call optimizations, see this article: JIT CLR tail-call conditions.
There are two basic kinds of recursions: head recursion and tail recursion.
In head recursion, a function makes its recursive call and then performs some more calculations, maybe using the result of the recursive call, for example.
In a tail recursive function, all calculations happen first and the recursive call is the last thing that happens.
Taken from this super awesome post. Please consider reading it.
Recursion means a function calling itself. For example:
(define (un-ended name)
(un-ended 'me)
(print "How can I get here?"))
Tail-Recursion means the recursion that conclude the function:
(define (un-ended name)
(print "hello")
(un-ended 'me))
See, the last thing un-ended function (procedure, in Scheme jargon) does is to call itself. Another (more useful) example is:
(define (map lst op)
(define (helper done left)
(if (nil? left)
done
(helper (cons (op (car left))
done)
(cdr left))))
(reverse (helper '() lst)))
In the helper procedure, the LAST thing it does if the left is not nil is to call itself (AFTER cons something and cdr something). This is basically how you map a list.
The tail-recursion has a great advantage that the interpreter (or compiler, dependent on the language and vendor) can optimize it, and transform it into something equivalent to a while loop. As matter of fact, in Scheme tradition, most "for" and "while" loop is done in a tail-recursion manner (there is no for and while, as far as I know).
Many people have already explained recursion here. I would like to cite a couple of thoughts about some advantages that recursion gives from the book “Concurrency in .NET, Modern patterns of concurrent and parallel programming” by Riccardo Terrell:
“Functional recursion is the natural way to iterate in FP because it avoids mutation of state. During each iteration, a new value is passed into the loop constructor instead to be updated (mutated). In addition, a recursive function can be composed, making your program more modular, as well as introducing opportunities to exploit parallelization."
Here also are some interesting notes from the same book about tail recursion:
Tail-call recursion is a technique that converts a regular recursive function into an optimized version that can handle large inputs without any risks and side effects.
NOTE The primary reason for a tail call as an optimization is to improve data locality, memory usage, and cache usage. By doing a tail call, the callee uses the same stack space as the caller. This reduces memory pressure. It marginally improves the cache because the same memory is reused for subsequent callers and can stay in the cache, rather than evicting an older cache line to make room for a new cache line.
This question has a lot of great answers... but I cannot help but chime in with an alternative take on how to define "tail recursion", or at least "proper tail recursion." Namely: should one look at it as a property of a particular expression in a program? Or should one look at it as a property of an implementation of a programming language?
For more on the latter view, there is a classic paper by Will Clinger, "Proper Tail Recursion and Space Efficiency" (PLDI 1998), that defined "proper tail recursion" as a property of a programming language implementation. The definition is constructed to allow one to ignore implementation details (such as whether the call stack is actually represented via the runtime stack or via a heap-allocated linked list of frames).
To accomplish this, it uses asymptotic analysis: not of program execution time as one usually sees, but rather of program space usage. This way, the space usage of a heap-allocated linked list vs a runtime call stack ends up being asymptotically equivalent; so one gets to ignore that programming language implementation detail (a detail which certainly matters quite a bit in practice, but can muddy the waters quite a bit when one attempts to determine whether a given implementation is satisfying the requirement to be "property tail recursive")
The paper is worth careful study for a number of reasons:
It gives an inductive definition of the tail expressions and tail calls of a program. (Such a definition, and why such calls are important, seems to be the subject of most of the other answers given here.)
Here are those definitions, just to provide a flavor of the text:
Definition 1 The tail expressions of a program written in Core Scheme are defined inductively as follows.
- The body of a lambda expression is a tail expression
- If
(if E0 E1 E2)is a tail expression, then bothE1andE2are tail expressions. - Nothing else is a tail expression.
Definition 2 A tail call is a tail expression that is a procedure call.
(a tail recursive call, or as the paper says, "self-tail call" is a special case of a tail call where the procedure is invoked itself.)
It provides formal definitions for six different "machines" for evaluating Core Scheme, where each machine has the same observable behavior except for the asymptotic space complexity class that each is in.
For example, after giving definitions for machines with respectively, 1. stack-based memory management, 2. garbage collection but no tail calls, 3. garbage collection and tail calls, the paper continues onward with even more advanced storage management strategies, such as 4. "evlis tail recursion", where the environment does not need to be preserved across the evaluation of the last sub-expression argument in a tail call, 5. reducing the environment of a closure to just the free variables of that closure, and 6. so-called "safe-for-space" semantics as defined by Appel and Shao.
In order to prove that the machines actually belong to six distinct space complexity classes, the paper, for each pair of machines under comparison, provides concrete examples of programs that will expose asymptotic space blowup on one machine but not the other.
(Reading over my answer now, I'm not sure if I'm managed to actually capture the crucial points of the Clinger paper. But, alas, I cannot devote more time to developing this answer right now.)
© 2022 - 2024 — McMap. All rights reserved.