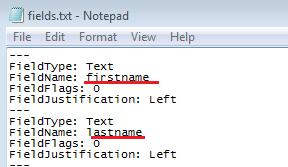
I am using the tool pdftk, I have got a editable PDF and I saw in the documentation the arguments dump_data_fields should show me the fields of the form.
I use this command (windows): pdftk my-pdf-form.pdf dump_data_fields
I am using the pdftk server edition.
Documentation: https://www.pdflabs.com/docs/pdftk-man-page/
The point is that the PDF is editable, it has got fields to write with Adobe PDF Viewer.