let's try to put up some intuition&sources together with the tfapproach.
General intuition:
Regression as presented here is a supervised learning problem. In it, as defined in Russel&Norvig's Artificial Intelligence, the task is:
given a training set (X, y) of m input-output pairs (x1, y1), (x2, y2), ... , (xm, ym), where each output was generated by an unknown function y = f(x), discover a function h that approximates the true function f
For that sake, the h hypothesis function combines somehow each x with the to-be-learned parameters, in order to have an output that is as close to the corresponding y as possible, and this for the whole dataset. The hope is that the resulting function will be close to f.
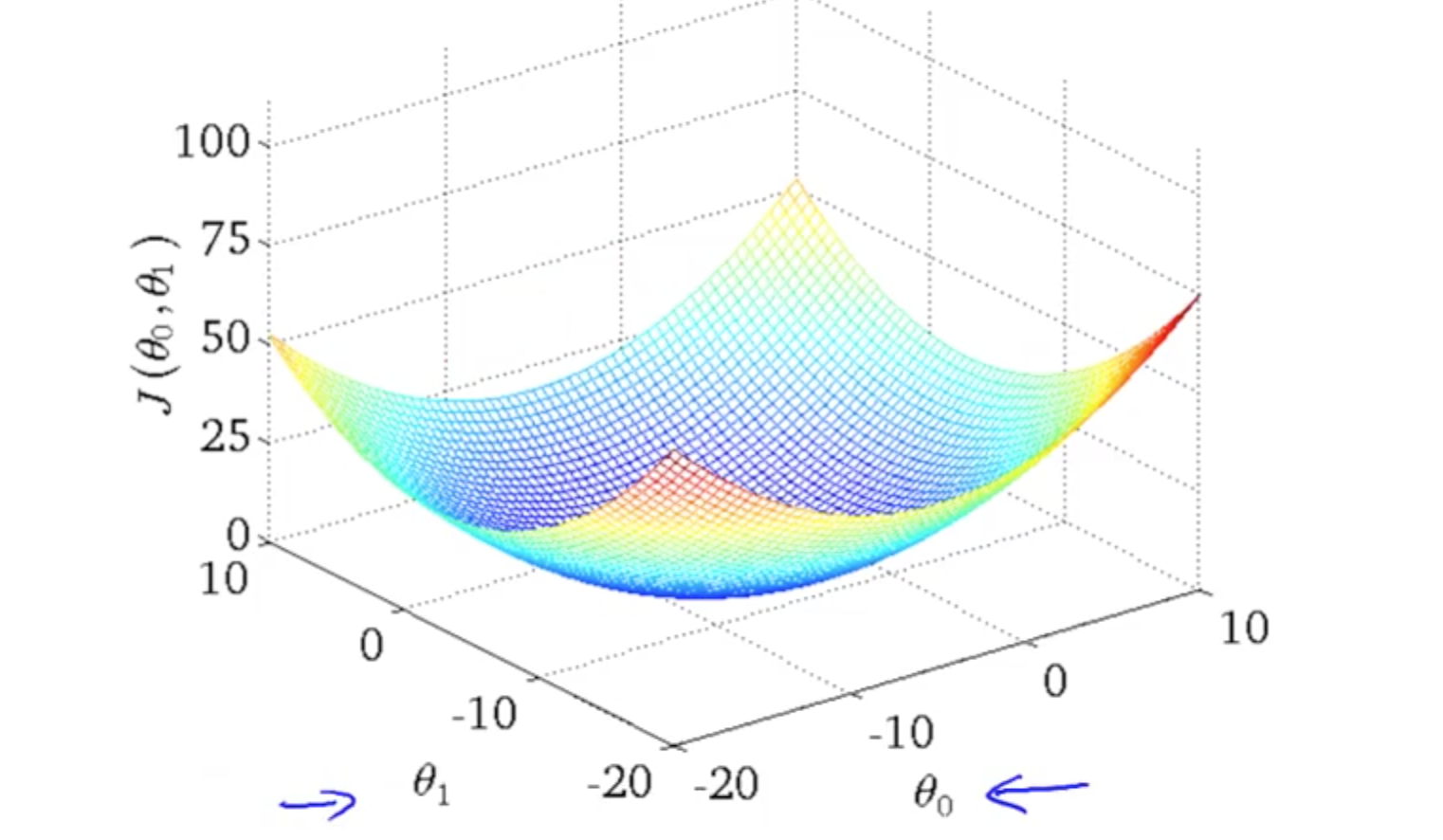
But how to learn this parameters? in order to be able to learn, the model has to be able to evaluate. Here comes the cost (also called loss, energy, merit...) function to play: it is a metric function that compares the output of h with the corresponding y, and penalizes big differences.
Now it should be clear what is exactly the "learning" process here: alter the parameters in order to achieve a lower value for the cost function.
Linear Regression:
The example that you are posting performs a parametric linear regression, optimized with gradient descent based on the mean squared error as cost function. Which means:
Parametric: The set of parameters is fixed. They are held in the exact same memory placeholders thorough the learning process.
Linear: The output of h is merely a linear (actually, affine) combination between the input x and your parameters. So if x and w are real-valued vectors of the same dimensionality, and b is a real number, it holds that h(x,w, b)= w.transposed()*x+b. Page 107 of the Deep Learning Book brings more quality insights and intuitions into that.
Cost function: Now this is the interesting part. The average squared error is a convex function. This means it has a single, global optimum, and furthermore, it can be directly found with the set of normal equations (also explained in the DLB). In the case of your example, the stochastic (and/or minibatch) gradient descent method is used: this is the preferred method when optimizing non-convex cost functions (which is the case in more advanced models like neural networks) or when your dataset has a huge dimensionality (also explained in the DLB).
Gradient descent: tf deals with this for you, so it is enough to say that GD minimizes the cost function by following its derivative "downwards", in small steps, until reaching a saddle point. If you totally need to know, the exact technique applied by TF is called automatic differentiation, kind of a compromise between the numeric and symbolic approaches. For convex functions like yours this point will be the global optimum, and (if your learning rate is not too big) it will always converge to it, so it doesn't matter which values you initialize your Variables with. The random initialization is necessary in more complex architectures like neural networks. There is some extra code regarding the management of the minibatches, but I won't get into that because it is not the main focus of your question.
The TensorFlow approach:
Deep Learning frameworks are nowadays about nesting lots of functions by building computational graphs (you may want to take a look at the presentation on DL frameworks that I did some weeks ago). For constructing and running the graph, TensoFlow follows a declarative style, which means that the graph has to be first completely defined and compiled, before it is deployed and executed. It is very reccommended to read this short wiki article, if you haven't yet. In this context, the setup is split in two parts:
Firstly, you define your computational Graph, where you put your dataset and parameters in memory placeholders, define the hypothesis and cost functions building on them, and tell tf which optimization technique to apply.
Then you run the computation in a Session and the library will be able to (re)load the data placeholders and perform the optimization.
The code:
The code of the example follows this approach closely:
Define the test data X and labels Y, and prepare a placeholder in the Graph for them (which is fed in the feed_dict part).
Define the 'W' and 'b' placeholders for the parameters. They have to be Variables because they will be updated during the Session.
Define pred (our hypothesis) and cost as explained before.
From this, the rest of the code should be clearer. Regarding the optimizer, as I said, tf already knows how to deal with this but you may want to look into gradient descent for more details (again, the DLB is a pretty good reference for that)
Cheers!
Andres
CODE EXAMPLES: GRADIENT DESCENT VS. NORMAL EQUATIONS
This small snippets generate simple multi-dimensional datasets and test both approaches. Notice that the normal equations approach doesn't require looping, and brings better results. For small dimensionality (DIMENSIONS<30k) is probably the preferred approach:
from __future__ import absolute_import, division, print_function
import numpy as np
import tensorflow as tf
####################################################################################################
### GLOBALS
####################################################################################################
DIMENSIONS = 5
f = lambda(x): sum(x) # the "true" function: f = 0 + 1*x1 + 1*x2 + 1*x3 ...
noise = lambda: np.random.normal(0,10) # some noise
####################################################################################################
### GRADIENT DESCENT APPROACH
####################################################################################################
# dataset globals
DS_SIZE = 5000
TRAIN_RATIO = 0.6 # 60% of the dataset is used for training
_train_size = int(DS_SIZE*TRAIN_RATIO)
_test_size = DS_SIZE - _train_size
ALPHA = 1e-8 # learning rate
LAMBDA = 0.5 # L2 regularization factor
TRAINING_STEPS = 1000
# generate the dataset, the labels and split into train/test
ds = [[np.random.rand()*1000 for d in range(DIMENSIONS)] for _ in range(DS_SIZE)] # synthesize data
# ds = normalize_data(ds)
ds = [(x, [f(x)+noise()]) for x in ds] # add labels
np.random.shuffle(ds)
train_data, train_labels = zip(*ds[0:_train_size])
test_data, test_labels = zip(*ds[_train_size:])
# define the computational graph
graph = tf.Graph()
with graph.as_default():
# declare graph inputs
x_train = tf.placeholder(tf.float32, shape=(_train_size, DIMENSIONS))
y_train = tf.placeholder(tf.float32, shape=(_train_size, 1))
x_test = tf.placeholder(tf.float32, shape=(_test_size, DIMENSIONS))
y_test = tf.placeholder(tf.float32, shape=(_test_size, 1))
theta = tf.Variable([[0.0] for _ in range(DIMENSIONS)])
theta_0 = tf.Variable([[0.0]]) # don't forget the bias term!
# forward propagation
train_prediction = tf.matmul(x_train, theta)+theta_0
test_prediction = tf.matmul(x_test, theta) +theta_0
# cost function and optimizer
train_cost = (tf.nn.l2_loss(train_prediction - y_train)+LAMBDA*tf.nn.l2_loss(theta))/float(_train_size)
optimizer = tf.train.GradientDescentOptimizer(ALPHA).minimize(train_cost)
# test results
test_cost = (tf.nn.l2_loss(test_prediction - y_test)+LAMBDA*tf.nn.l2_loss(theta))/float(_test_size)
# run the computation
with tf.Session(graph=graph) as s:
tf.initialize_all_variables().run()
print("initialized"); print(theta.eval())
for step in range(TRAINING_STEPS):
_, train_c, test_c = s.run([optimizer, train_cost, test_cost],
feed_dict={x_train: train_data, y_train: train_labels,
x_test: test_data, y_test: test_labels })
if (step%100==0):
# it should return bias close to zero and parameters all close to 1 (see definition of f)
print("\nAfter", step, "iterations:")
#print(" Bias =", theta_0.eval(), ", Weights = ", theta.eval())
print(" train cost =", train_c); print(" test cost =", test_c)
PARAMETERS_GRADDESC = tf.concat(0, [theta_0, theta]).eval()
print("Solution for parameters:\n", PARAMETERS_GRADDESC)
####################################################################################################
### NORMAL EQUATIONS APPROACH
####################################################################################################
# dataset globals
DIMENSIONS = 5
DS_SIZE = 5000
TRAIN_RATIO = 0.6 # 60% of the dataset isused for training
_train_size = int(DS_SIZE*TRAIN_RATIO)
_test_size = DS_SIZE - _train_size
f = lambda(x): sum(x) # the "true" function: f = 0 + 1*x1 + 1*x2 + 1*x3 ...
noise = lambda: np.random.normal(0,10) # some noise
# training globals
LAMBDA = 1e6 # L2 regularization factor
# generate the dataset, the labels and split into train/test
ds = [[np.random.rand()*1000 for d in range(DIMENSIONS)] for _ in range(DS_SIZE)]
ds = [([1]+x, [f(x)+noise()]) for x in ds] # add x[0]=1 dimension and labels
np.random.shuffle(ds)
train_data, train_labels = zip(*ds[0:_train_size])
test_data, test_labels = zip(*ds[_train_size:])
# define the computational graph
graph = tf.Graph()
with graph.as_default():
# declare graph inputs
x_train = tf.placeholder(tf.float32, shape=(_train_size, DIMENSIONS+1))
y_train = tf.placeholder(tf.float32, shape=(_train_size, 1))
theta = tf.Variable([[0.0] for _ in range(DIMENSIONS+1)]) # implicit bias!
# optimum
optimum = tf.matrix_solve_ls(x_train, y_train, LAMBDA, fast=True)
# run the computation: no loop needed!
with tf.Session(graph=graph) as s:
tf.initialize_all_variables().run()
print("initialized")
opt = s.run(optimum, feed_dict={x_train:train_data, y_train:train_labels})
PARAMETERS_NORMEQ = opt
print("Solution for parameters:\n",PARAMETERS_NORMEQ)
####################################################################################################
### PREDICTION AND ERROR RATE
####################################################################################################
# generate test dataset
ds = [[np.random.rand()*1000 for d in range(DIMENSIONS)] for _ in range(DS_SIZE)]
ds = [([1]+x, [f(x)+noise()]) for x in ds] # add x[0]=1 dimension and labels
test_data, test_labels = zip(*ds)
# define hypothesis
h_gd = lambda(x): PARAMETERS_GRADDESC.T.dot(x)
h_ne = lambda(x): PARAMETERS_NORMEQ.T.dot(x)
# define cost
mse = lambda pred, lab: ((pred-np.array(lab))**2).sum()/DS_SIZE
# make predictions!
predictions_gd = np.array([h_gd(x) for x in test_data])
predictions_ne = np.array([h_ne(x) for x in test_data])
# calculate and print total error
cost_gd = mse(predictions_gd, test_labels)
cost_ne = mse(predictions_ne, test_labels)
print("total cost with gradient descent:", cost_gd)
print("total cost with normal equations:", cost_ne)
{kind=link}
Wandbare random on the start, also for same dataset I get diffirent results:1st: Training cost= 56.1033 W= 1.4661 b= 0.8666822nd: Training cost= 56.2247 W= 1.4747 b= 0.42918Also how can I use that data for predictions? – Wickham