I am trying to speed up the segmentation model(unet-mobilenet-512x512). I converted my tensorflow model to tensorRT with FP16 precision mode. And the speed is lower than I expected. Before the optimization i had 7FPS on inference with .pb frozen graph. After tensorRT oprimization I have 14FPS.
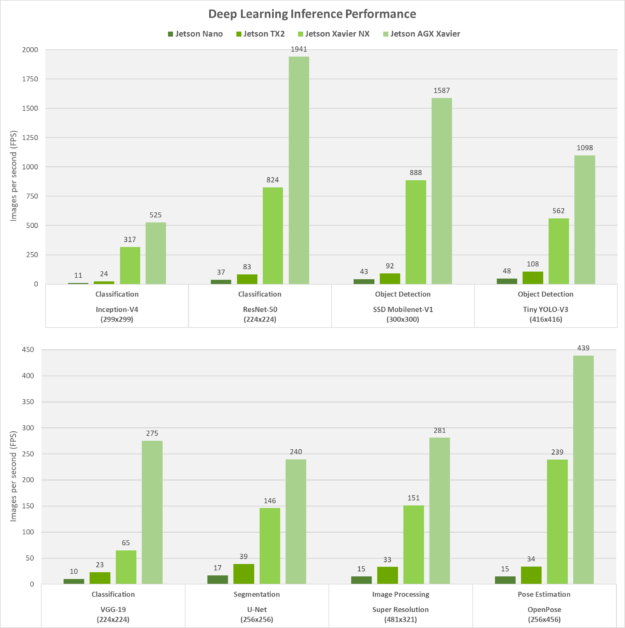
Here is benchmark results of Jetson NX from their site
You can see, that unet 256x256 segmentation speed is 146 FPS. I thought, the speed of my unet512x512 should be 4 times slower in the worst case.
Here is my code for optimizing tensorflow saved model using TensorRt:
import numpy as np
from tensorflow.python.compiler.tensorrt import trt_convert as trt
import tensorflow as tf
params = trt.DEFAULT_TRT_CONVERSION_PARAMS
params = params._replace(
max_workspace_size_bytes=(1<<32))
params = params._replace(precision_mode="FP16")
converter = tf.experimental.tensorrt.Converter(input_saved_model_dir='./model1', conversion_params=params)
converter.convert()
def my_input_fn():
inp1 = np.random.normal(size=(1, 512, 512, 3)).astype(np.float32)
yield [inp1]
converter.build(input_fn=my_input_fn) # Generate corresponding TRT engines
output_saved_model_dir = "trt_graph2"
converter.save(output_saved_model_dir) # Generated engines will be saved.
print("------------------------freezing the graph---------------------")
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
saved_model_loaded = tf.saved_model.load(
output_saved_model_dir, tags=[tf.compat.v1.saved_model.SERVING])
graph_func = saved_model_loaded.signatures[
tf.compat.v1.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY]
frozen_func = convert_variables_to_constants_v2(
graph_func)
frozen_func.graph.as_graph_def()
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir="./",
name="unet_frozen_graphTensorRt.pb",
as_text=False)
I downloaded the repository, that was used for Jetson NX benchmarking ( https://github.com/NVIDIA-AI-IOT/jetson_benchmarks ), and the speed of unet256x256 really is ~146FPS. But there is no pipeline to optimize the model.
How can I get the similar results? I am looking for the solutions to get speed of my model(unet-mobilenet-512x512) close to 30FPS
Maybe I should run inference in other way(without tensorflow) or change some converting parameters?
Any suggestions, thanks