I have a DF like
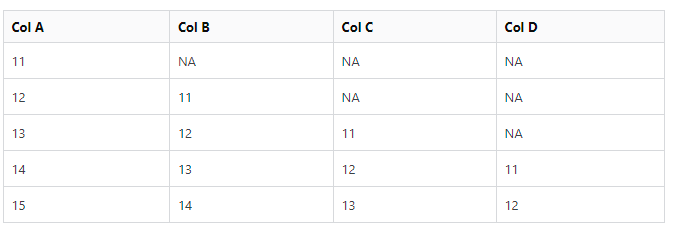
Now I want to replace The Col B = NA with 15 since that is the missing value. Col C first NA with 14 and second NA with 15. Col D first NA with 13, second NA with 14 and third NA with 15. So the numbers follow a sequence up to down or down to up.
Reproducible Sample Data
structure(list(`Col A` = c(11, 12, 13, 14, 15), `Col B` = c(NA,
11, 12, 13, 14), `Col C` = c(NA, NA, 11, 12, 13), `Col D` = c(NA,
NA, NA, 11, 12)), row.names = c(NA, -5L), class = c("tbl_df",
"tbl", "data.frame"))