I am the author of qdap. The polarity function was designed for much smaller data sets. As my role shifted I began to work with larger data sets. I needed fast and accurate (these two things are in opposition to each other) and have since developed a break away package sentimentr. The algorithm is optimized to be faster and more accurate than qdap's polarity.
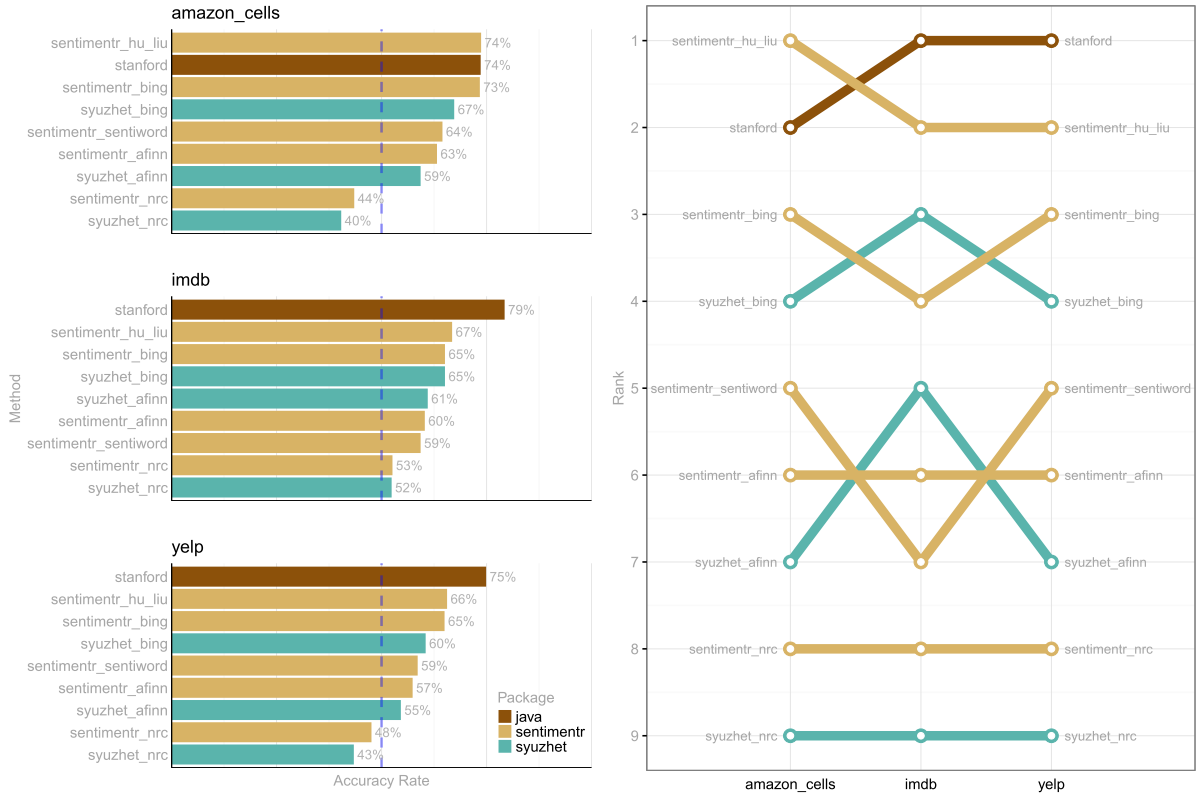
As it stands now you have 5 dictionary based (or trained alorithm based) approached to sentiment detection. Each has it's drawbacks (-) and pluses (+) and is useful in certain circumstances.
- qdap +on CRAN; -slow
- syuzhet +on CRAN; +fast; +great plotting; -less accurate on non-literature use
- sentimentr +fast; +higher accuracy; -GitHub only
- stansent (stanford port) +most accurate; -slower
- tm.plugin.sentiment -archived on CRAN; -I couldn't get it working easily
I show time tests on sample data for the first 4 choices from above in the code below.
Install packages and make timing functions
I use pacman because it allows the reader to just run the code; though you can replace with install.packages & library calls.
if (!require("pacman")) install.packages("pacman")
pacman::p_load(qdap, syuzhet, dplyr)
pacman::p_load_current_gh(c("trinker/stansent", "trinker/sentimentr"))
pres_debates2012 #nrow = 2912
tic <- function (pos = 1, envir = as.environment(pos)){
assign(".tic", Sys.time(), pos = pos, envir = envir)
Sys.time()
}
toc <- function (pos = 1, envir = as.environment(pos)) {
difftime(Sys.time(), get(".tic", , pos = pos, envir = envir))
}
id <- 1:2912
Timings
## qdap
tic()
qdap_sent <- pres_debates2012 %>%
with(qdap::polarity(dialogue, id))
toc() # Time difference of 18.14443 secs
## sentimentr
tic()
sentimentr_sent <- pres_debates2012 %>%
with(sentiment(dialogue, id))
toc() # Time difference of 1.705685 secs
## syuzhet
tic()
syuzhet_sent <- pres_debates2012 %>%
with(get_sentiment(dialogue, method="bing"))
toc() # Time difference of 1.183647 secs
## stanford
tic()
stanford_sent <- pres_debates2012 %>%
with(sentiment_stanford(dialogue))
toc() # Time difference of 6.724482 mins
For more on timings and accuracy see my sentimentr README.md and please star the repo if it's useful. The viz below captures one of the tests from the README:
![enter image description here]()