As we know, some JIT allows reordering for object initialization, for example,
someRef = new SomeObject();
can be decomposed into below steps:
objRef = allocate space for SomeObject; //step1
call constructor of SomeObject; //step2
someRef = objRef; //step3
JIT compiler may reorder it as below:
objRef = allocate space for SomeObject; //step1
someRef = objRef; //step3
call constructor of SomeObject; //step2
namely, step2 and step3 can be reordered by JIT compiler. Even though this is theoretically valid reordering, I was unable to reproduce it with Hotspot(jdk1.7) under x86 platform.
So, Is there any instruction reordering done by the Hotspot JIT comipler that can be reproduced?
Update: I did the test on my machine(Linux x86_64,JDK 1.8.0_40, i5-3210M ) using below command:
java -XX:-UseCompressedOops -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand="print org.openjdk.jcstress.tests.unsafe.UnsafePublication::publish" -XX:CompileCommand="inline, org.openjdk.jcstress.tests.unsafe.UnsafePublication::publish" -XX:PrintAssemblyOptions=intel -jar tests-custom/target/jcstress.jar -f -1 -t .*UnsafePublication.* -v > log.txt
and I can see the tool reported something like:
[1] 5 ACCEPTABLE The object is published, at least 1 field is visible.
That meant an observer thread saw an uninitialized instance of MyObject.
However,I did NOT see assembly code generated like @Ivan's:
0x00007f71d4a15e34: mov r11d,DWORD PTR [rbp+0x10] ;getfield x
0x00007f71d4a15e38: mov DWORD PTR [rax+0x10],r11d ;putfield x00
0x00007f71d4a15e3c: mov DWORD PTR [rax+0x14],r11d ;putfield x01
0x00007f71d4a15e40: mov DWORD PTR [rax+0x18],r11d ;putfield x02
0x00007f71d4a15e44: mov DWORD PTR [rax+0x1c],r11d ;putfield x03
0x00007f71d4a15e48: mov QWORD PTR [rbp+0x18],rax ;putfield o
There seems to be no compiler reordering here.
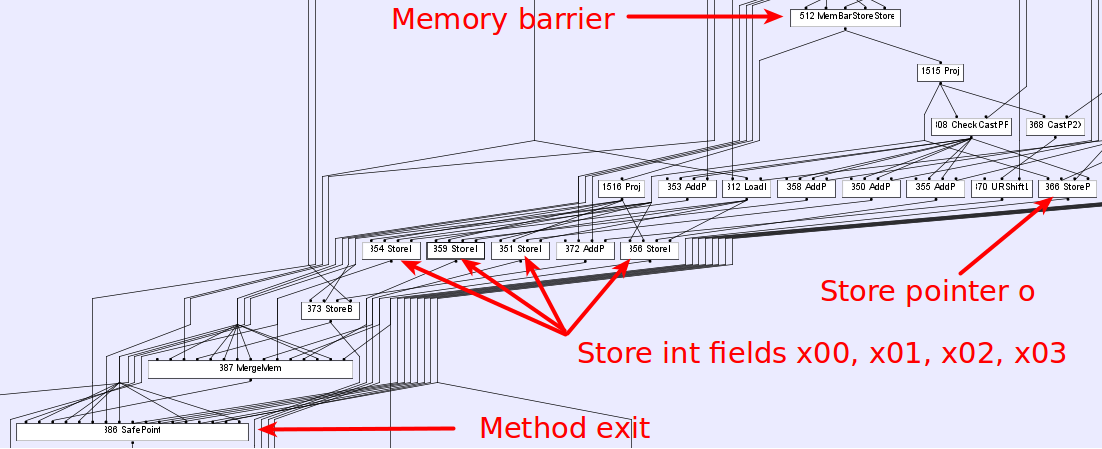
Update2: @Ivan corrected me. I used wrong JIT command to capture the assembly code.After fixing this error, I can grap below assembly code:
0x00007f76012b18d5: mov DWORD PTR [rax+0x10],ebp ;*putfield x00
0x00007f76012b18d8: mov QWORD PTR [r8+0x18],rax ;*putfield o
; - org.openjdk.jcstress.tests.unsafe.generated.UnsafePublication_jcstress$Runner_publish::call@94 (line 156)
0x00007f76012b18dc: mov DWORD PTR [rax+0x1c],ebp ;*putfield x03
Apparently, the compiler did the reordering which caused an unsafe publication.
-XX:+PrintAssemblyand grep or change compiler hint to something like-XX:CompileCommand="print org.openjdk.jcstress.tests.unsafe.generated.UnsafePublication_jcstress*::call"– Volatile