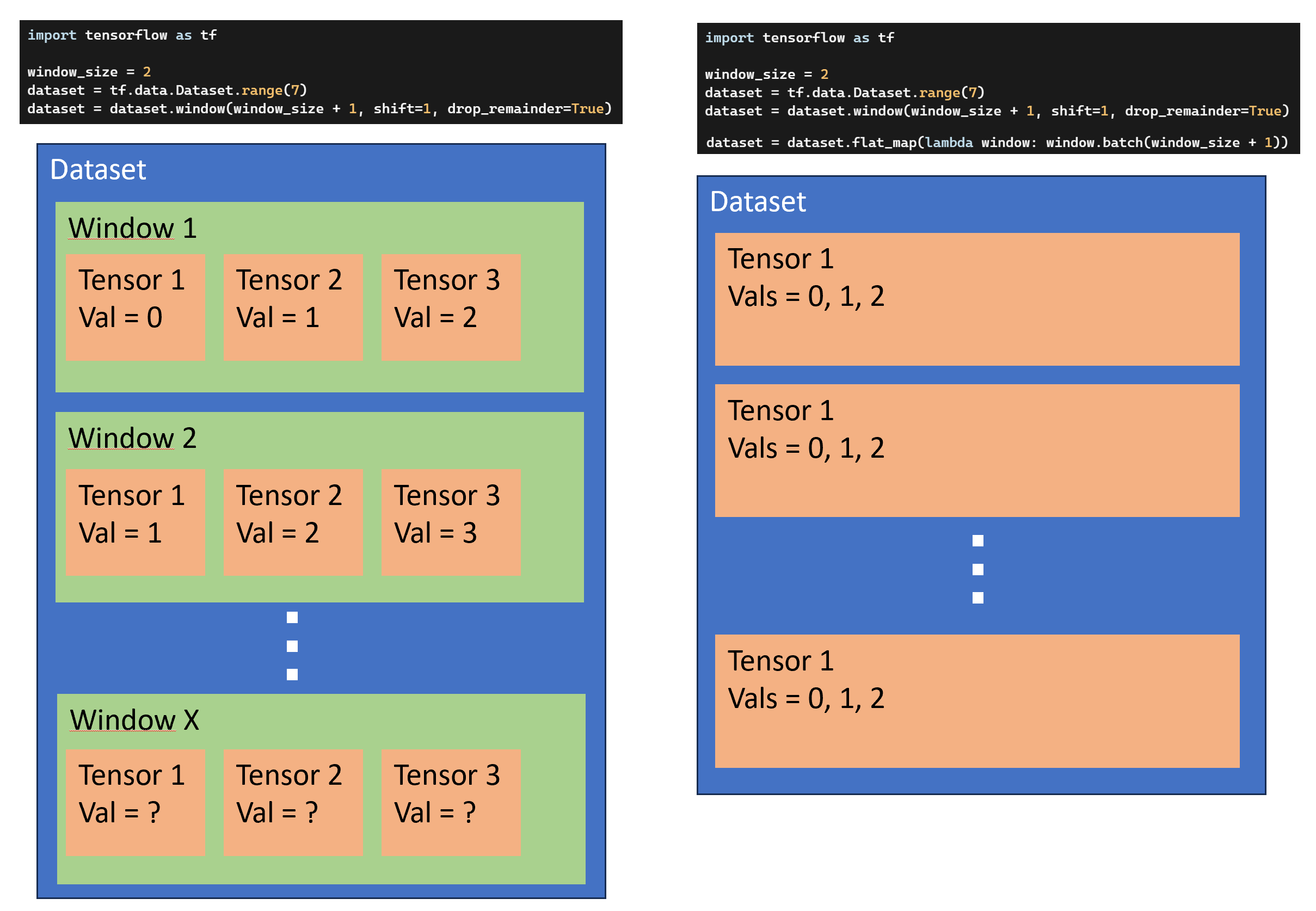
I would break down the operations into smaller parts to really understand what is happening, since applying window to a dataset actually creates a dataset of windowed datasets containing tensor sequences:
import tensorflow as tf
window_size = 2
dataset = tf.data.Dataset.range(7)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
for i, window in enumerate(dataset):
print('{}. windowed dataset'.format(i + 1))
for w in window:
print(w)
1. windowed dataset
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
2. windowed dataset
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
3. windowed dataset
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
4. windowed dataset
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
5. windowed dataset
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
tf.Tensor(6, shape=(), dtype=int64)
Notice how the window is always shifted by one position due to the parameter shift=1. Now, the operation flat_map is used here to flatten the dataset of datasets into a dataset of elements; however, you still want to keep the windowed sequences you created so you divide the dataset according to the window parameters using dataset.batch:
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
for w in dataset:
print(w)
tf.Tensor([0 1 2], shape=(3,), dtype=int64)
tf.Tensor([1 2 3], shape=(3,), dtype=int64)
tf.Tensor([2 3 4], shape=(3,), dtype=int64)
tf.Tensor([3 4 5], shape=(3,), dtype=int64)
tf.Tensor([4 5 6], shape=(3,), dtype=int64)
You could also first flatten the dataset of datasets and then apply batch if you want to create the windowed sequences:
dataset = dataset.flat_map(lambda window: window).batch(window_size + 1)
Or only flatten the dataset of datasets:
dataset = dataset.flat_map(lambda window: window)
for w in dataset:
print(w)
tf.Tensor(0, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(1, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(2, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(3, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
tf.Tensor(4, shape=(), dtype=int64)
tf.Tensor(5, shape=(), dtype=int64)
tf.Tensor(6, shape=(), dtype=int64)
But that is probably not what you want. Regarding this line in your question: dataset = dataset.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1])), it is pretty trivial. It simply splits the data into sequences and labels, using the last element of each sequence as the label:
dataset = dataset.shuffle(2).map(lambda window: (window[:-1], window[-1]))
for w in dataset:
print(w)
(<tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 2])>, <tf.Tensor: shape=(), dtype=int64, numpy=3>)
(<tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 3])>, <tf.Tensor: shape=(), dtype=int64, numpy=4>)
(<tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 4])>, <tf.Tensor: shape=(), dtype=int64, numpy=5>)
(<tf.Tensor: shape=(2,), dtype=int64, numpy=array([4, 5])>, <tf.Tensor: shape=(), dtype=int64, numpy=6>)
(<tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>, <tf.Tensor: shape=(), dtype=int64, numpy=2>)