If you are using Spark 2.0.4 and running your code on AWS EMR cluster, then please follow the below steps:-
1) Download the Redshift JDBC jar by using the below command:-
wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.20.1043/RedshiftJDBC4-no-awssdk-1.2.20.1043.jar
Refernce:- AWS Document
2) Copy the below-mentioned code in a python file and then replace the required values with your AWS resource:-
import pyspark
from pyspark.sql import SQLContext
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark._jsc.hadoopConfiguration().set("fs.s3.awsAccessKeyId", "access key")
spark._jsc.hadoopConfiguration().set("fs.s3.awsSecretAccessKey", "secret access key")
sqlCon = SQLContext(spark)
df = sqlCon.createDataFrame([
(1, "A", "X1"),
(2, "B", "X2"),
(3, "B", "X3"),
(1, "B", "X3"),
(2, "C", "X2"),
(3, "C", "X2"),
(1, "C", "X1"),
(1, "B", "X1"),
], ["ID", "TYPE", "CODE"])
df.write \
.format("com.databricks.spark.redshift") \
.option("url", "jdbc:redshift://HOST_URL:5439/DATABASE_NAME?user=USERID&password=PASSWORD") \
.option("dbtable", "TABLE_NAME") \
.option("aws_region", "us-west-1") \
.option("tempdir", "s3://BUCKET_NAME/PATH/") \
.mode("error") \
.save()
3) Run the below spark-submit command:-
spark-submit --name "App Name" --jars RedshiftJDBC4-no-awssdk-1.2.20.1043.jar --packages com.databricks:spark-redshift_2.10:2.0.0,org.apache.spark:spark-avro_2.11:2.4.0,com.eclipsesource.minimal-json:minimal-json:0.9.4 --py-files python_script.py python_script.py
Note:-
1) The Public IP address of the EMR node (on which the spark-submit job will run) should be allowed in the inbound rule of security group of Reshift cluster.
2) Redshift cluster and the S3 location used under "tempdir" should be there in the same geo-location. Here in the above example, both the resources are in us-west-1.
3) If the data is sensitive then do make sure to secure all the channels. To make the connections secure please follow the steps mentioned here
under configuration.
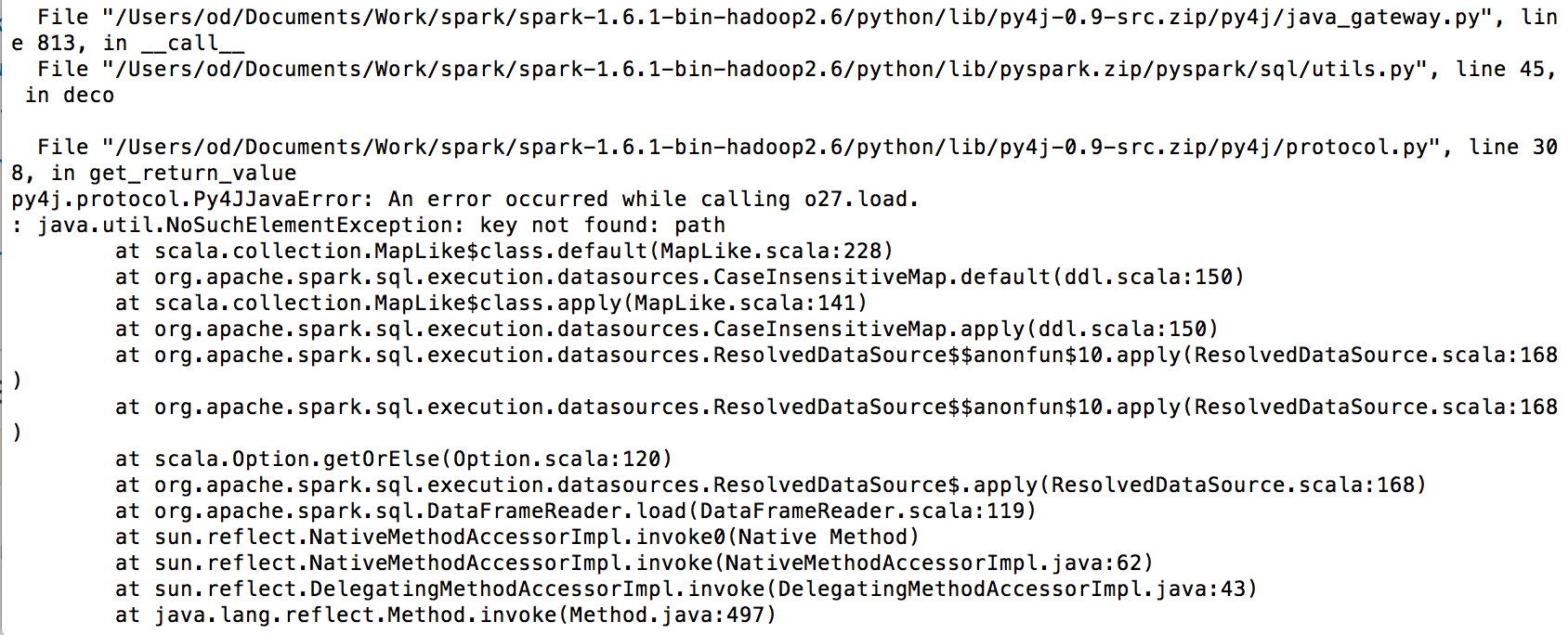
java.lang.IllegalArgumentException: Invalid hostname in URI s3n://somewhereorjava.lang.IllegalArgumentException: Invalid hostname in URI s3://somwehereors3agives mejava.lang.NoClassDefFoundError: com/amazonaws/SdkClientException at org.apache.hadoop.fs.s3a.S3AFileSystem.initialize(S3AFileSystem.java:235):@ – Debera