Changing aspect ratios and scales won't help improve the detection accuracy of small objects (since the original scale is already small enough, e.g. min_scale = 0.2). The most important parameter you need to change is feature_map_layout. feature_map_layout determines the number of feature maps (and their sizes) and their corresponding depth (channels). But sadly this parameter cannot be configured in the pipeline_config file, you will have to modify it directly in the feature extractor.
Here is why this feature_map_layout is important in detecting small objects.
![enter image description here]()
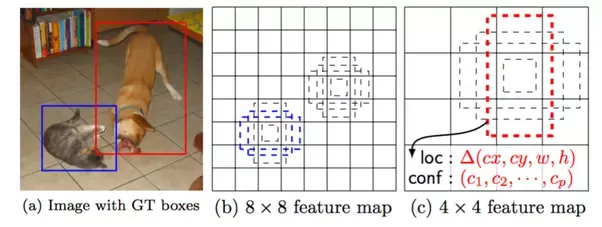
In the above figure, (b) and (c) are two feature maps of different layouts. The dog in the groundtruth image matches the red anchor box on the 4x4 feature map, while the cat matches the blue one on the 8x8 feature map. Now if the object you want to detect is the cat's ear, then there would be no anchor boxes to match the object. So the intuition is: If no anchor boxes match an object, then the object simply won't be detected. To successfully detect the cat's ear, what you need is probably a 16x16 feature map.
Here is how you can make the change to feature_map_layout. This parameter is configured in each specific feature extractor implementation. Suppose you use ssd_mobilenet_v1_feature_extractor, then you can find it in this file.
feature_map_layout = {
'from_layer': ['Conv2d_11_pointwise', 'Conv2d_13_pointwise', '', '',
'', ''],
'layer_depth': [-1, -1, 512, 256, 256, 128],
'use_explicit_padding': self._use_explicit_padding,
'use_depthwise': self._use_depthwise,
}
Here the there are 6 feature maps of different scales. The first two layers are taken directly from mobilenet layers (hence the depth are both -1) while the rest four result from extra convolutional operations. It can be seen that the lowest level feature map comes from the layer Conv2d_11_pointwise of mobilenet. Generally the lower the layer, the finer the feature map features, and the better for detecting small objects. So you can change this Conv2d_11_pointwise to Conv2d_5_pointwise (why this? It can be found from the tensorflow graph, this layer has bigger feature map than layer Conv2d_11_pointwise), it should help detect smaller objects.
But better accuracy comes at extra cost, the extra cost here is the detect speed will drop a little because there are more anchor boxes to take care of. (Bigger feature maps). Also since we choose Conv2d_5_pointwise over Conv2d_11_pointwise, we lose the detection power of Conv2d_11_pointwise.
If you don't want to change the layer but simply add an extra feature map, e.g. making it 7 feature maps in total, you will have to change num_layers int the config file to 7 too. You can think of this parameter as the resolution of the detection network, the more lower level layers, the finer the resolution will be.
Now if you have performed above operations, one more thing to help is to add more images with small objects. If this is not feasible, at least you can try adding data augmentation operations like random_image_scale