I can read a csv file in which there is a column containing Chinese characters (other columns are English and numbers). However, Chinese characters don't display correctly. see photo below
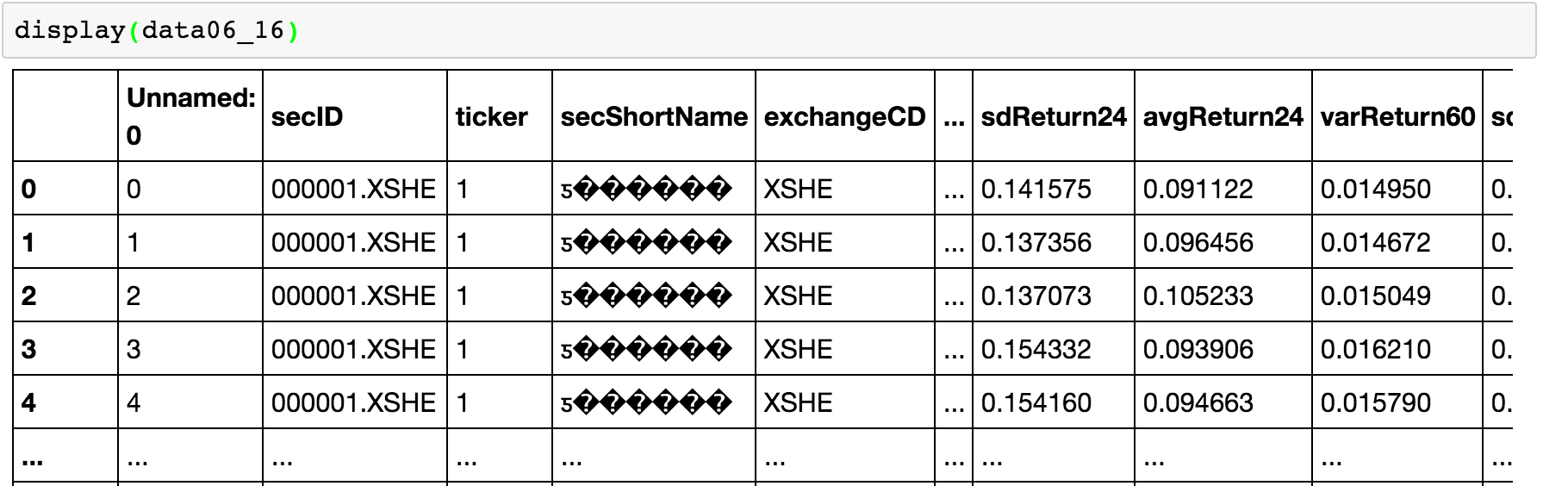
I loaded the csv file with pd.read_csv().
Either display(data06_16) or data06_16.head() won't display Chinese characters correctly.
I tried to add the following lines into my .bash_profile:
export LC_ALL=zh_CN.UTF-8
export LANG=zh_CN.UTF-8
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
but it doesn't help.
Also I have tried to add encoding arg to pd.read_csv():
pd.read_csv('data.csv', encoding='utf_8')
pd.read_csv('data.csv', encoding='utf_16')
pd.read_csv('data.csv', encoding='utf_32')
These won't work at all.
How can I display the Chinese characters properly?
Chineselanguages -- Sayencoding='gb2312'? – EuhemerismUnicodeDecodeError: 'gb2312' codec can't decode bytes in position 2-3: illegal multibyte sequence– Bigler